[Rate Limit - step 5] Sliding Window 알고리즘 구현 (rate limiting)
필자는 현재 API서버를 열심히 개발 하고 있다. 개발한 서비스가 트래픽을 많이 받다보니, 트래픽을 적절히 제한하지 않았을 때 장애가 발생했고, 그에 따라 API의 Rate Limit을 구현해야 했다.
공부하다보니 흥미가 생겨 나중에 내가 다시 챙겨보기 위해 글을 정리하려고 한다.
Rate Limit시리즈의 목차는 다음과 같다.
[Rate Limit - step 1] Rate Limit이란? (개념, Throttling, 분산환경에서의 구현)
[Rate Limit - step 2] Leaky Bucket 알고리즘 구현 (rate limiting) (p.s. memory estimation 하는 법)
[Rate Limit - step 3] Token Bucket 알고리즘 구현 (rate limiting)
[Rate Limit - step 4] Fixed Window 알고리즘 구현 (rate limiting)
[Rate Limit - step 5] Sliding Window 알고리즘 구현 <- 이번 글
본 글은 step 3로 Rate Limit의 대표적인 알고리즘 중 하나인 Token Bucket 알고리즘에 대해 알아본다. 개인적으로 이전 시리즈를 읽고 보는 것을 추천한다. 물론 이것만 보고도 알 수 있지만, 더 잘 이해할 수 있을거라 생각한다.
Sliding Window 알고리즘
Fixed Window의 단점인 기간 경계의 편향 문제로 인한 burst of traffic문제를 해결하기 위해 window의 위치를 바꿔 단점을 보완한 알고리즘이다. rate을 계산하기 위해 timestamped log를 기록하면서, 이전 window의 request rate과 현재 window의 timestamp의 request rate을 weight를 먹여 계산하는 방식이다.
예를 들어 보겠다.
만약 현재 Window기준 25%정도만큼의 시간만 흘렀다고 했을때, 현재 rate을 계산할 때 이전 윈도우의 총 rate의 75%와 현재까지의 요청 수를 합하여 현재의 윈도우를 계산한다.
시간당 100개의 request를 허용하는 예제를 아래 그림과 함께 설명해보겠다.
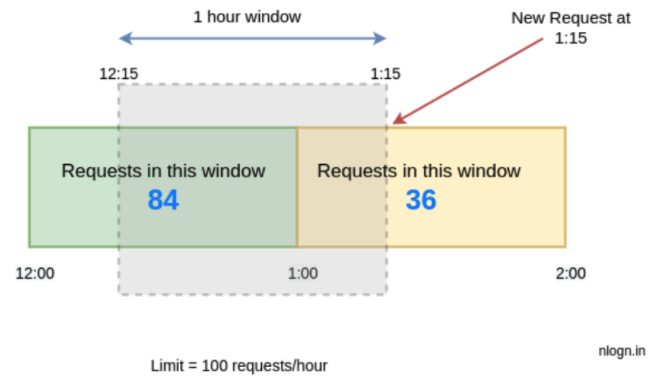
만약 요청 1개가 1:15에 왔다고 했을 때, 다음과 같이 현재 window의 rate을 approximate 하게계산한다.
limit = 100 requests/hour
rate = 84 * ((60-15)/60) + 36
= 84 * 0.75 + 36
= 99
rate < 100
hence, we will accept this request.현재 윈도우의 rate을 계산해보니[12:15–1:15) 99가 나왔다. 우리 기준인 100개 미만이기 때문에, request는 허용된다. 하지만 바로 직후에 오는 요청들은 block된다.
Sliding window알고리즘은 previous window에 대한 approximation을 하기 때문에 정확한 계산을 하진 못한다. 하지만 매우 높은 정확도를 가지고 있다고 한다. 실제로 27,000개의 유저로부터 4억 개의 request를 보내는 테스트를 진행했을 때 0.003%의 request만 잘못 허용될 정도로 높은 정확도를 가지고 있다고 한다.
Sliding Window 장점
1. burst of traffic을 방지할 수 있다.
2. 일정한 수준의 request rate를 유지할 수 있다.
3. 다른 알고리즘에 비핸 메모리 사용량이 높지만, 그래도 여전히 memory efficient하다.
Sliding Window 단점
1. window의 요청 건에 대한 로그를 관리해야 하기 때문에 구현과 메모리 비용이 fixed window에 비해 높다.
- counter당 2개의 숫자만 기록하면 되기 때문 (timestamp, count)
2. distributed system에서 활용하기에 공유해야 하는 포인트가 늘어난다.
Sliding Window 샘플 코드
Python으로 코드를 작성했고, 자세한 설명은 주석에 정리해두었으니 참고해서 이해하길 바란다.
from time import time, sleep
class SlidingWindow:
def __init__(self, capacity, time_unit, forward_callback, drop_callback):
self.capacity = capacity # number of the allowed packets that can pass through in a second
self.time_unit = time_unit # length of time unit in seconds
self.forward_callback = forward_callback # this function is called when the packet is being forwarded
self.drop_callback = drop_callback # this function is called when the packet should be dropped
self.cur_time = time() # the edge of our current time unit (hour, minute) (current time)
self.pre_count = capacity # previous counter. we pre-fill this to prevent bursting at the beginning of the rate limitter
self.cur_count = 0 #the current counter that will get filled as new requests come in
def handle(self, packet):
if (time() - self.cur_time) > self.time_unit: #if the current time unit is passed, switch over to a new time unit
self.cur_time = time()
self.pre_count = self.cur_count
self.cur_count = 0
ec = (self.pre_count * (self.time_unit - (time() - self.cur_time)) / self.time_unit) + self.cur_count #calculate the estimated count based on the given formula
if (ec > self.capacity): #drop the packet if ec is bigger thant the capacity
return self.drop_callback(packet)
self.cur_count += 1 #otherwise, add one to the current counter and forward the packet
return self.forward_callback(packet)
def forward(packet):
print("Packet Forwarded: " + str(packet))
def drop(packet):
print("Packet Dropped: " + str(packet))
throttle = SlidingWindow(5, 1, forward, drop)
packet = 0
while True:
sleep(0.1)
throttle.handle(packet)
packet += 1
자 이렇게 Rate Limit 시리즈의 마지막인 Sliding Window 알고리즘에 대해 알아보았다. 필자는 실제로 본 시리즈에서 소개한 알고리즘을 현재 내가 개발하고 있는 API 서비스에 적용해보았고, 서비스의 안정성을 높여볼 수 있었다. 알고리즘을 자세히 이해하고, rate limit에 대해 이해해보는 것을 추천한다.

참고자료
https://dev.to/satrobit/rate-limiting-using-the-sliding-window-algorithm-5fjn