
쿼카러버의 기술 블로그
[Rate Limit - step 2] Leaky Bucket 알고리즘 구현(rate limiting) (p.s. memory estimation 하는 법) 본문
[Rate Limit - step 2] Leaky Bucket 알고리즘 구현(rate limiting) (p.s. memory estimation 하는 법)
quokkalover 2022. 4. 7. 22:26필자는 현재 API서버를 열심히 개발 하고 있다. 개발한 서비스가 트래픽을 많이 받다보니, 트래픽을 적절히 제한하지 않았을 때 장애가 발생했고, 그에 따라 API의 Rate Limit을 구현해야 했다.
공부하다보니 흥미가 생겨 나중에 내가 다시 챙겨보기 위해 글을 정리하려고 한다.
Rate Limit시리즈의 목차는 다음과 같다.
[Rate Limit - step 1] Rate Limit이란? (개념, Throttling, 분산환경에서의 구현)
[Rate Limit - step 2] Leaky Bucket 알고리즘 구현 (rate limiting) (p.s. memory estimation 하는 법) <- 이번 글
[Rate Limit - step 3] Token Bucket 알고리즘 구현 (rate limiting)
[Rate Limit - step 4] Fixed Window 알고리즘 구현 (rate limiting)
[Rate Limit - step 5] Sliding Window 알고리즘 구현 (rate limiting)
본 글은 Step 2로, Rate Limit구현시 Memory를 예상하는 법과 대표적인 알고리즘 중 하나인 Leaky Bucket 알고리즘에 대해 알아본다.

Memory Estimation
Rate Limit을 구현할 때는 내가 설계한 rate limit이 사용할 메모리양을 계산해 볼 필요가 있다. 자칫 잘못 설계할 경우 OOM이슈가 발생하는 끔찍한 상황을 겪을 수 있다.
Hash table을 사용하는 간단하게 분당 IP rate limit을 구현한다고 가정했을 때를 예로 들어 보겠다.
이때 Hash table의 키(key)는 {IP}가 될 수 있고, 값(value)은 [Count, StartTime]이 될 수 있다.
한 record당 필요한 메모리의 양을 계산해보자
- IP : 16byte라고 가정하고,
- Count : 2byte (~6만5천)
- StartTime : 2byte (분과 초단위 값만 있으면 되기 때문에)
- Lock : 4byte 레코드 수정할 때마다 mutex사용할 때
= 총 24byte가 필요하다.
여기에 Hash Table이 각 record마다 추가로 20byte가 필요하다고 했을 때, 만약 백만명의 유저를 관리해야 한다고 하면
(24+20)byte * 1,000,000 = 약 44MB가 필요하다.
Leaky Bucket 알고리즘
이제 leaky bucket 알고리즘에 대해 알아볼 시간이다.
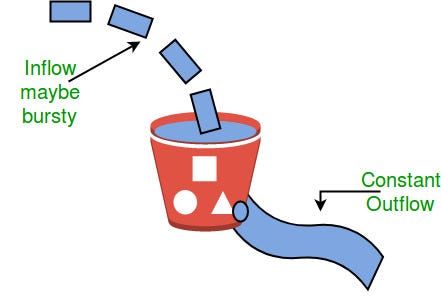
Leaky bucket은 flow control의 대표적인 알고리즘이다. constant한 처리속도와 처리할 수 있는 요청의 양을 제어하는 방법이다.
- 양동이의 구멍이 서버가 요청을 처리할 수 있는 지속적인 속도를 의미하고,
- 양동이의 깊이는 서버가 일정한 기간 동안 처리할 수 있는 요청의 양을 의미하는 은유적인 표현이다.
- 고정 용량의 양동이에 물이 들어오면 버킷에 담기고 그 담긴물은 일정량 비율로 떨어진다(constant rate).
다음과 같이 동작한다.
- 요청은 FIFO Queue에 담겨 미리 규정된 속도로 처리된다. (들어온 순으로)
- FIFO Queue가 가득차 있지 않은 경우에는 요청을 받아들인다.
- FIFO Queue가 가득차있을 때 요청이 들어오게 되면 클라이언트에게 에러를 리턴한다.
아래 그림과 함께 예로 들어 설명해보자.
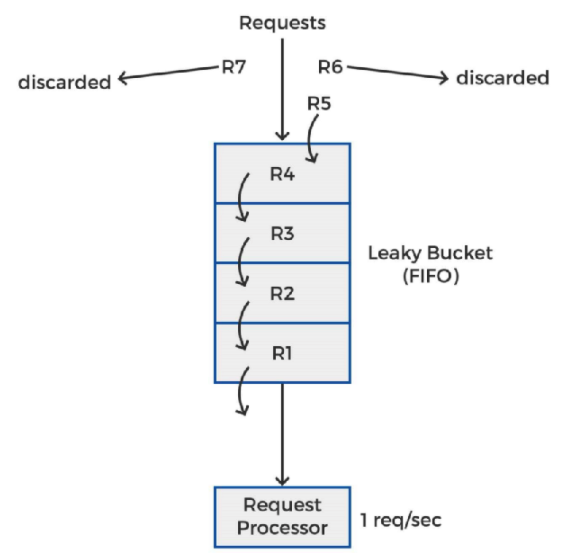
- R1, R2, R3, R4, R5, R6, R7 순으로 요청이 들어온다고 가정
- Leaky Bucket의 Capacity는 4개의 request
- 초당 1번의 요청만 처리
R1이 들어오자마자 처리되고 R2, R3, R4, R5로 Leaky Bucket이 이미 가득차 있는 상황에, R6, R7요청이 오게 되면, 처리할 수 있는 양이 초당 1개의 요청밖에 안되기 때문에 R6, R7에 대해서는 에러를 리턴한다.
Leaky Bucket의 장점
- 일정한(constant) 속도(rate)로 요청을 처리한다
- 구현이 쉽다
- memory efficient하다 (queue의 사이즈가 정해져 있기 때문)
Leaky Bucket의 단점
- 요청의 양에 비해 처리속도가 너무 늦을 경우, 새로운 요청들은 처리되지 못하는 starve 현상
Leaky Bucket 코드 예시
Leaky Bucket을 python 코드로 구현해봤다. 주석을 잘 달아뒀으니, 자세히 읽어보면서 참고하길 바란다.
from time import time, sleep
import math
class LeakyBucket:
def __init__(self, rate, burst, period, unit):
# period in unit (s, m, h)
#unit (s, m, h) -> minimum time unit is seconds(s)
self.rate = rate # how many HTTP requests can be made in a given period
self.burst = burst # maxium number of HTTP requests can be made in a given period
self.period = self.calc_period(period, unit)
self.current = 0
self.exchange_rate = self.period / self.rate # 1 request vs time in second (s) exchange rate based on given period and rate
self.round_decimal = int(math.log(1 / self.exchange_rate, 10))+ 1
self.burst_offset = self.burst * self.exchange_rate # maximum number of request * exchange_rate => rate limit in time in second form
def calc_period(self, period, unit):
if unit == "s":
return period
elif unit == "m":
return period * 60
elif unit == "h":
return period * 3600
else:
raise ValueError("invalid unit")
def handle(self, n):
cost = n * self.exchange_rate # request's cost in second
now = math.floor(time())
tat = max(now, self.current)
new_tat = round(tat + cost, self.round_decimal) # use round up because can't get 0 when calculating diff due to floating point issue
allow_at = new_tat - self.burst_offset
diff = now - allow_at
remaining = diff / self.exchange_rate
if remaining < 0:
return False
self.current = new_tat
return True
packet = 0
throttle = LeakyBucket(120, 120, 1, "s")
while True:
sleep(0.1)
print(throttle.handle(1))- 10ms마다 bucket이 가득 차있는지 확인하고 아니면 채워주는 형태로 동작
- Start()에서 돌아가는 고 루틴은 1초마다 bucket을 비워버림
- 이렇게 비워주는 이유는 채널을 채워줘야 되는데 혹시나 갯수가 다 안비워지면 deadlock이 걸릴 수 있기 때문
- 물론 length체크해서, (len(lb.b)하면 채워져있는 양만큼 나오니까 그거만큼만 채워주게도 할 수 있음)
자 이렇게 Leaky Bucket알고리즘에 대해 알아보았다. 내가 직접 코드들 살펴보면서 구현한다고 시간을 꽤나 쓴 것 같다. 그래도 매우 흥미로운 시간이었고, Leaky Bucket은 많은 회사에서 사용되는 알고리즘이기 때문에 한 번쯤 알아둘 필요가 있다고 생각한다.
자 이제 Leaky Bucket과 거의 유사한 Token Bucket 알고리즘에 대해 알아볼 시간이다. Leaky Bucket은 시간을 기준으로 계산해봤다면 Token Bucket은 말 그대로 Bucket에 채워진 Token을 기준으로 rate limiting을 하는데, 궁금하다면 다음 글로 넘어가자~!

참고자료:
https://www.mimul.com/blog/about-rate-limit-algorithm/
https://www.quinbay.com/blog/understanding-rate-limiting-algorithms
'[Infra & Server] > API' 카테고리의 다른 글
| [Python] 파이썬 부하테스터 Locust 개념 정리 및 꿀팁 소개 (0) | 2022.08.11 |
|---|---|
| [Rate Limit - step 5] Sliding Window 알고리즘 구현 (rate limiting) (0) | 2022.04.07 |
| [Rate Limit - step 4] Fixed Window 알고리즘 구현 (rate limiting) (0) | 2022.04.07 |
| [Rate Limit - step 3] Token Bucket 알고리즘 구현 (rate limiting) (1) | 2022.04.07 |
| [Rate Limit - step 1] Rate Limit이란? (소개, Throttling, 구현시 주의사항 등) (2) | 2022.04.07 |



