
쿼카러버의 기술 블로그
[Rate Limit - step 1] Rate Limit이란? (소개, Throttling, 구현시 주의사항 등) 본문
[Rate Limit - step 1] Rate Limit이란? (소개, Throttling, 구현시 주의사항 등)
quokkalover 2022. 4. 7. 22:13
필자는 현재 API서버를 열심히 개발 하고 있다. 개발한 서비스가 트래픽을 많이 받다보니, 트래픽을 적절히 제한하지 않았을 때 장애가 발생했고, 그에 따라 API의 Rate Limit을 구현해야 했다.
공부하다보니 흥미가 생겨 나중에 내가 다시 챙겨보기 위해 글을 정리하려고 한다.
Rate Limit시리즈의 목차는 다음과 같다.
[Rate Limit - step 1] Rate Limit이란? (개념, Throttling, 분산환경에서의 구현) <- 이번 글
[Rate Limit - step 2] Leaky Bucket 알고리즘 구현 (rate limiting) (p.s. memory estimation 하는 법)
[Rate Limit - step 3] Token Bucket 알고리즘 구현 (rate limiting)
[Rate Limit - step 4] Fixed Window 알고리즘 구현 (rate limiting)
[Rate Limit - step 5] Sliding Window 알고리즘 구현 (rate limiting)
자 볼게 많다. Rate Limit을 구현하는 사람이라면 다 이해해야 할 개념이기 때문에, 침착하게 살펴보자

Rate Limit이란?
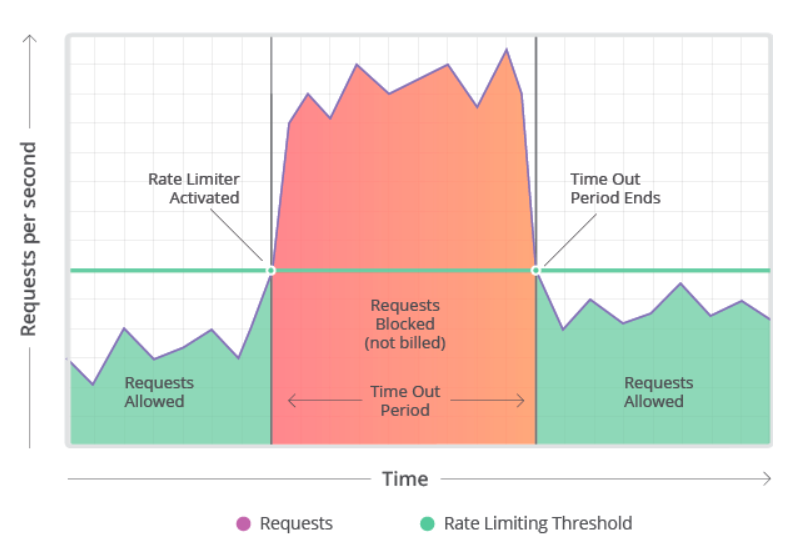
Rate Limit이란 서버가 특정 임계치까지만 클라이언트의 요청을 허용하는 정책을 의미한다. 서버가 제공할 수 있는 자원에는 제한이 있기 때문에 안정적으로 서비스를 제공하기 위해 사용되는 대표적인 혼잡 제어 기법이다. 예를 들어 서버에 호출할 수 있는 횟수를 1분당 60회(60회가 임계치)로 임계치를 정해두었다면, 60회를 넘어선 순간부터는 요청을 처리해주지 않고 에러를 리턴하는 정책을 세울 수 있다. 이를 Throttling이라고도 표현하는데, 쉽게 말하면 정해진 시간 동안 처리할 수 있는 operation의 수를 정하는 것이다.
실제로 규모가 큰 서비스(Linkedin, Github, Facebook)에는 대부분 Rate Limit 정책을 사용하고 있을만큼 Rate Limit은 API 설계에 있어서 필수적이다.
Rate limit이 필요한 이유
1. 서비스의 안정성 및 성능 보장 : 서버가 다운되는 등의 사고를 미연에 방지하고, 기대한 성능으로 동작하도록 할 수 있다.
2. 서비스의 가용성(availability) 확보 : 과도한 트래픽으로부터 서비스를 보호할 수 있다.
3. 보안 : 로그인, 프로모션 코드와 같이 security intensive한 기능을 brute force attack으로 부터 보호한다.
4. 운영 비용 관리 : 트래픽 비용이 서비스 예산을 넘지 않게, 무분별하게 auto scaling하지 않고 scale의 virtual cap을 두고 제한 한다.
5. 공정성과 합리성 : 특정 클라이언트가 서버의 자원을 독점하지 못하도록 하는 공정성과 합리성 확보
6. Business Model : rate에 따라 요금을 다르게 부과하는 비즈니스 모델 활용 가능
Throttling 구현 방식
유저의 요청 수가 임계치를 넘었을때, 이를 제한 하는 방식은 크게 3가지로 나눠볼 수 있다. 공통적으로는 유저의 요청수가 초과하면 HTTP status “429 — Too many requests”. 리턴하게 된다.
1. Hard Throttling : throttle limit을 엄격하게 관리 (1개라도 넘으면 안됨)
2. Soft Throttling : 특정 percentage까지는 throttle limit을 넘기는 것을 허용. 예를 들어 rate limit이 분당 100회인데, 10%로 잡으면 110회까지는 허용
3. Elastic or Dynamic Throttling : 서버 자원에 여유가 있을 때는 thorttle limit을 넘기더라도 요청을 허용함
Rate Limit 구현시 요구 조건
Rate limit을 구현할 때 요구 조건은 크게 구현과 운영의 측면으로 나누어 고려할 수 있다.
기능 측면
1. 클라이언트가 서버에 요청할 수 있는 횟수를 특정 임계치까지만 허용한다. (예: 1분당 30회)
2. 클라이언트의 요청횟수가 정책적으로 정해둔 임계치를 넘어설 경우에는 에러를 리턴해야 한다.
운영 측면
1. 안정성 및 가용성 : Rate Limit이 동작하는 서버는 안정적으로 동작해야 한다. 수강신청이나 Ddos공격과 같이 특정 시간에 요청이 급증하는 경우에도 동작해야 한다. 또한 유저수가 많아진다 해도 OOM과 같은 이슈가 발생하지 않아야 한다.
2. 성능 : Rate Limit서버로 인해 서버의 처리량이 과도하게 늘어나거나 응답시간이 지연되지 않고 빠르게 Rate Limit을 처리할 수 있어야 한다.
Ratelimit 그래서 어디에 쓰는데?
Ratelimit은 주로 유저별로 rate limit을 걸긴하지만 아래와 같은 상황도 고려해볼 수 있다.
1. 유저별 Rate Limit : userID, API Key, IP address 등을 기준으로 특정 유저가 API에 요청할 수 있는 수를 제한.
2. Concurrent 서버 rate limit : 특정 유저에 의해 맺을 수 있는 parallel session의 수. DDos공격 등을 막기 위해 사용
Rate Limit 구현시 주의사항
리턴 메시지
Rate Limit을 적용하려면 RFC6585에 429 Too Many Request HTTP 상태코드를 사용하라고 제안한다.
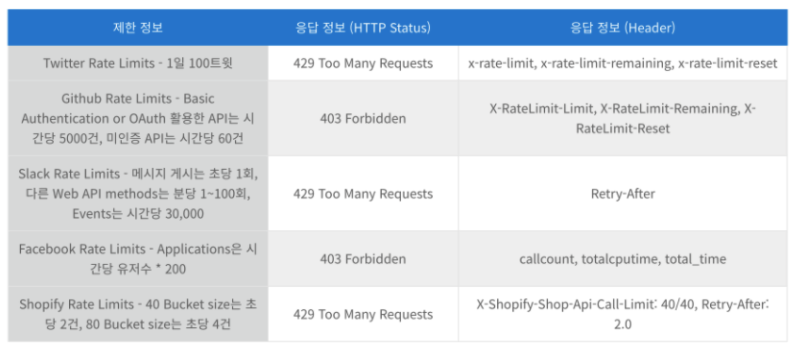
또한 RateLimit-Limit(허용되는 요청의 최대 수), RateLimit-Remaining(남은 요청 수), RateLimit-Reset(요청 최댓값이 재설정될때까지의 시간)정보를 Header에 같이 보내주면 좋다.
아래는 여러 기업들이 리턴하는 방식의 예다.
적절한 알고리즘 선택
Rate Limit 알고리즘은 트래픽 패턴을 잘 분석하고, 적합한 알고리즘을 선택하는 것이 매우 중요하다.
예를 들어 분산시스템에서의 활용, 트래피 체증에 민감하지 않은 경우 등에 따라 다른 알고리즘의 선택이 필요하다. 내가 조사한 바에 따르면 트래픽에 민감하지 않은 경우에는 Token Bucket, 그 외에는 Fixed Window나 Sliding Window알고리즘을 선택한다고 한다.
본 글에서는 알고리즘에 대해 다루지 않고, 다음 글에서 어떤 알고리즘이 있는지, 그리고 어떻게 구현할 수 있는지에 대해 다루어보도록 하겠다.
Rate Limit 아키텍처 설계
Application Server앞 단에서 웹서버가 Rate Limiter와 통신
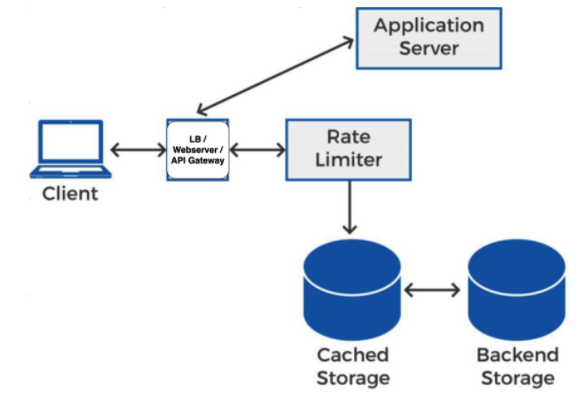
위 그림에서 보이듯
1. Load Balancer는 Rate Limiter에게 Client의 rate limit을 조회한다.
2. Rate Limiter는 rate limiting data를 cached storage와 backend storage에서 관리하며, LoadBalancer의 요청에 따라 클라이언트의 요청이 rate을 초과했는지 여부를 리턴한다
3. 만약 초과했으면 LB는 Application Server에 요청을 전달하지 않고 Client의 요청을 거절한다.
분산환경에서 구현시 문제점
분산환경에서 구현할 때는 정답은 없는 것 같다. 트래픽 패턴에 맞추어 적절한 설정을 해야 하는데, 일단 어떤 문제점이 있는지 알아보자.
Inconsistency
여러개의 앱서버들이 분산되어 다른 region에서 동작하고 있는 경우에는, global rate limiter가 필요하다. 하지만 이렇게 분산돼있는 앱서버에서 global rate limiter를 활용하려면 어떻게 해야 할까? 두 가지 방법이 있다.
1. Sticky Session : 로드밸런서에 sticky session을 두고 특정 유저는 특정 node로만 request를 가도록 해서, local rate limiter를 활용하도록 한다. 하지만 이 방법은 scaling할 수 없을 뿐더러 이 node가 꺼졌을때 대응을 할 수 없다는 단점이 있다.
2. Centralized Data Store : Redis나 Cassandra와 같은 중앙화된 data store를 사용해서 rate limit정보를 저장할 수 있다. 하지만 이 경우에는 지연시간이 문제가 될 수 있지만, DB자체가 분산화된 환경에 최적화된 것들이기 때문에 좀 더 우아한 해결책이 될 수 있다.
Race Condition
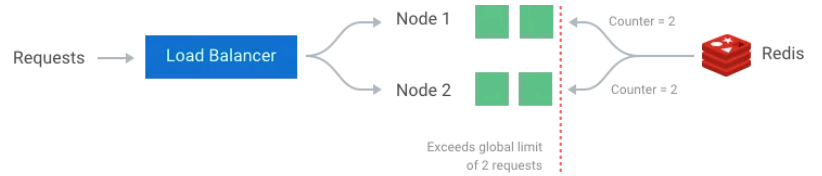
get-then-set 방법으로 rate limit을 구현할 경우 concurrency가 높아지는 경우에는 race condition이 발생할 수 있다. 각 node에서 동시에 같은 counter를 저장하려고 하는 경우, counter가 증가하지 못하는 문제가 발생할 수 있기 때문이다.
이를 해결하라면 read-write operation에 lock을 활용할 수 있지만 성능 문제(지연 시간)가 문제가 될 수 있다.
분산환경에서 Centralized DB를 활용한 rate synchronization
위 그림은 조금 단순화 한 개념이고, 실제로 race condition을 고려한 상세한 아키텍처는 아래와 같다
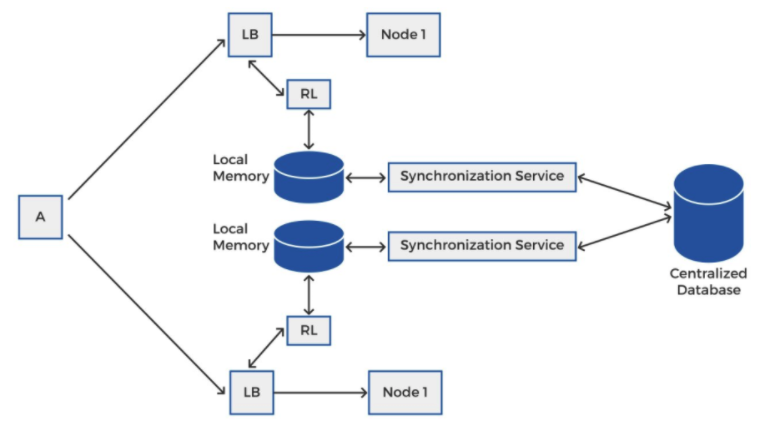
많은 global lock으로 인한 latency를 줄이기 위해, local memory에 rate을 업데이트하고, 주기적으로 centralized storage와 동기화하는 방식이다. 이 아키텍처의 포인트는 local memory와 centralized database와의 inconsistency를 해결해주는 synchronization service가 별도로 있어야 한다는 점이다.
자 본 글에서는 Rate Limit이 무엇인지, 그리고 구현할 때의 주의사항 뿐만 아니라 분산환경에서의 구현방식에 대해 설명했다. 이제 Rate Limiting이 무엇이고, 어떤 식으로 설계해야 하는지 알았으니, 대표적인 알고리즘과 구현 예시를 알아보자!

참고자료
https://github.com/ermanimer/design-patterns/blob/main/token-bucket/tokenbucket.go
'[Infra & Server] > API' 카테고리의 다른 글
| [Python] 파이썬 부하테스터 Locust 개념 정리 및 꿀팁 소개 (0) | 2022.08.11 |
|---|---|
| [Rate Limit - step 5] Sliding Window 알고리즘 구현 (rate limiting) (0) | 2022.04.07 |
| [Rate Limit - step 4] Fixed Window 알고리즘 구현 (rate limiting) (0) | 2022.04.07 |
| [Rate Limit - step 3] Token Bucket 알고리즘 구현 (rate limiting) (1) | 2022.04.07 |
| [Rate Limit - step 2] Leaky Bucket 알고리즘 구현(rate limiting) (p.s. memory estimation 하는 법) (0) | 2022.04.07 |



