[HTTP] keep alive란? (persistent connection에 대하여)

HTTP 관련 서비스를 구현하다보면 persistent connection을 빼놓을 수 없다. 그렇다고 필자가 완벽히 이걸 다 이해한건 아니고 공부중이다 하핫. 본 글에서는 persistent connection의 기본적인 개념을 소개하고 HTTP/1.0의 keep-alive에 대해서 알아본다.

Persistent Connection
HTTP에서 persistent connection이 필요한 이유는 무엇일까? 대표적인 이유로 site locality가 있다. site locality란 웹에서 특정 페이지를 보여주기 위해 서버에 연속적으로 이미지 request를 보내는 것 처럼, 서버에 연속적으로 동일한 클라이언트가 여러 요청을 보낼 가능성이 높은 경우를 의미한다.
이러한 니즈가 계속됨에 따라 HTTP/1.1부터는 HTTP 어플리케이션이 TCP connection을 요청 마다 close하지 않고 재사용할 수 있는 방법을 제공한다. 이렇게 요청이 처리된 후에도 connection을 유지하는 경우를 persistent connection이라고 표현한다. 다시 말해 persistent connection이란 통신의 주체인 서버와 클라이언트 중 하나가 명시적으로 connection을 close하고나 정책적으로 close될 때까지 계속해서 connection을 유지하는 경우를 의미한다.
Persistent connection이 필요한 이유
기본적으로 persistent connection을 사용하게 되면 TCP 연결을 맺기 위해 SYN과 ACK을 주고받는 three-way handshake을 매 요청마다 맺을 필요가 없어진다. 따라서 아래와 같은 장점이 있다.
1) 네트워크 혼잡 감소 : TCP, SSL/TCP connection request수가 줄어들면서
2) 네트워크 비용 감소 : 여러 개의 connection으로 하나의 client요청을 serving하는 것보다는 한 개의 connection으로 client요청을 serving하는게 더 효율적이다.
3) latency감소 : 3-way handshake을 맺으면서 필요한 round-trip이 줄어들기 때문에 그만큼 latency가 감소한다.
Persistent connection과 parallel connection의 차이
parallel connection이란 병렬적으로 동시에 여러 connection을 맺는 것을 의미한다. 물론 parallel connection은 throughput을 늘려주긴 하지만 다음의 문제가 있다.
1) 매번 매 요청때마다 새로운 connection을 open하고 close해야 하기 때문에 네트워크 연결에 더 많은 시간과 bandwidth가 소모된다.
2) TCL slow start로 인해한 성능 저하
3) parallel connection을 맺을 수 있는 수의 제한
하지만 persistent connection을 활용하게 되면 connection establishment에 소모되는 비용을 줄이면서 위와 같은 문제를 완화시킬 수 있다. 물론 persistent connection은 자칫 잘못 관리하게 되면 너무 많은 idle connection이 생기게되면서 서버에 과도한 부하가 생길 수 있기 때문에 설정을 주의해야 한다.
또한 parallel connection이 단점이 있다고 해서 persistent connection이 이를 대체하는게 아니라, 둘을 적절히 혼용해서 사용할 수 있어야 한다. 실제로 많은 web 어플리케이션들은 적은 수의 parallel connection을 persistent하게 유지하고 있다.
HTTP keep alive란?
HTTP keep-alive는 위에서 설명한 persistent connection을 맺는 기법 중 하나로, HTTP/1.0+부터 지원하고 있다. 하나의 TCP connection을 활용해서 여러개의 HTTP request/response를 주고받을 수 있도록 해준다. keep-alive옵션은 설계상 여러 문제점(e.g. proxy 문제) 이 생기면서 HTTP/1.1부터 사용되고 있지 않지만 여전히 많은 웹 어플리케이션에서 사용하고 있기 때문에 이해해둘 필요가 있다.
기본적으로 HTTP/1.1은 persistent connection을 지원하는 반면에 HTTP/1.0 connection은 하나의 request에 응답할 때마다 connection을 close하도록 설정돼있다.
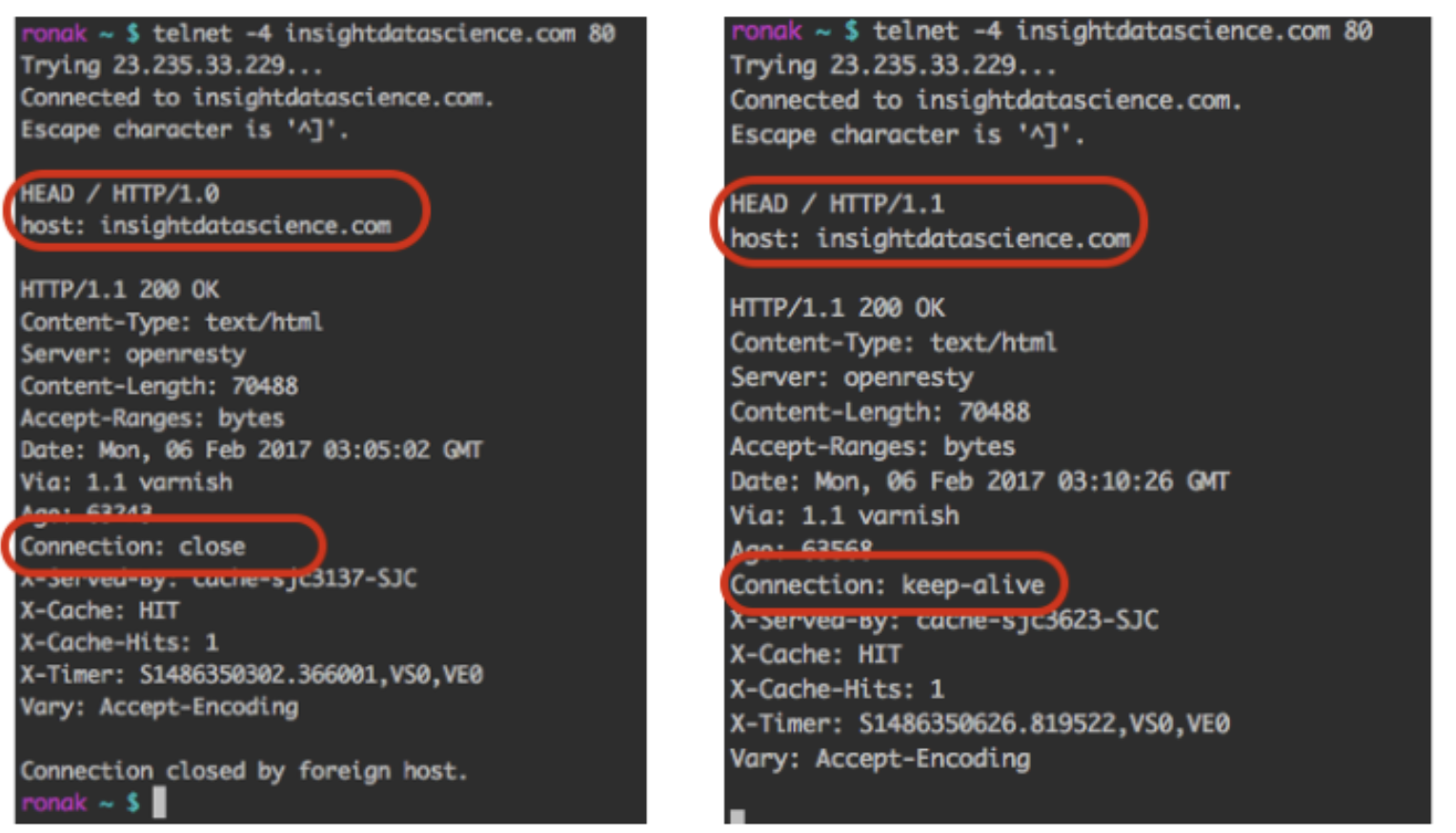
이에 따라 연속적으로 여러 request를 보낼 때마다 계속해서 connection을 맺었다 끊었다 해야하는 부하가 생긴다.
하지만 keep-alive옵션을 활용하면 persistent하게 connection을 유지할 수 있도록하여 불필요한 연결의 맺고 끊음을 최소화시켜 네트워크 부하를 아래 사진 처럼 줄일 수 있다.

keep-alive 옵션 사용 방법
keep-alive 옵션을 통해 persistent connection을 맺기 위해서는 HTTP header에 아래와 같이 입력해주어야 한다. 만약 서버에서 keep-alive connection을 지원하는 경우에는 동일한 헤더를 response에 담아 보내주고, 지원하지 않으면 헤더에 담아 보내주지 않는다. 만약 서버의 응답에 해당 헤더가 없을 경우 client는 지원하지 않는다고 가정하고 connection을 재사용하지 않는다.
HTTP/1.1 200 OK
Connection: Keep-Alive
Keep-Alive: timeout=5, max=1000max(MaxKeepAliveRequests) : keep-alive connection을 통해서 주고받을 수 있는 request의 최대 갯수. 이 수보다 더 많은 요청을 주고 받을 경우에는 connection은 close된다.timeout(KeepAlivetimeout) : 커넥션이 idle한 채로 얼마동안 유지될 것인가를 의미한다. 이 시간이 지날 동안 request가 없을 경우에 connection은 close된다.
그 외 keep-alive 옵션 관련 규칙들
1) persistent한 connection을 유지하기 위해서는 클라이언트 측에서 모든 요청에 위에 언급한 헤더를 담아 보내야 한다. 만약 한 요청이라도 생략될 경우 서버는 연결을 close한다.
2) 서버 또한 마찬가지로 persistent하게 요청을 주고받다가 response에 keep-alive 관련 헤더가 담겨오지 않을때는 클라이언트 측에서 서버가 persistent connection을 맺고있지 않다고 판단할 수 있다.
3) 정확한 Content-length를 사용해야 한다. 하나의 connection을 계속해서 재사용해야 하는데, 특정 요청의 종료를 판단할 수 없기 때문이다.
4) Connection 헤더를 지원하지 않는 proxy에는 사용할 수 없다.
5) 클라이언트는 언제든 connection이 close될 수 있기 때문에 retry로직을 준비해두는게 바람직하다.
Keep-alive옵션 사용 성능 비교 테스트
keep-alive사용하지 않고 매 요청마다 connection을 맺는 코드
매 요청마다 connection을 새로 맺는다.
#!/usr/bin/env python
# Using same TCP connection for all HTTP requests
import os
import json
import time
import logging
import requests
from requests.auth import HTTPBasicAuth
logging.basicConfig(level=logging.DEBUG)
start_time = time.time()
def get_venmo_data(limit):
session = requests.Session()
url = "https://venmo.com/api/v5/public?limit={}"
for i in range(50):
response = session.get(url.format(limit))
response_dict = json.loads(response.text)
for transaction in response_dict["data"]:
print(unicode(transaction["message"]))
url = response_dict["paging"]["next"] + "&limit={}"
if __name__ == "__main__":
limit = 1
get_venmo_data(limit)
print("--- %s seconds ---" % (time.time() - start_time))Average time with new connections: 5번 돌린 결과 평균 22초
keep-alive사용하지 않고 매 요청마다 connection을 맺는 코드
python에서는 requests.Session()을 통해 persistent connection을 맺을 수 있다.
#!/usr/bin/env python
# Using new TCP connection for each HTTP request
import os
import json
import time
import logging
import requests
from requests.auth import HTTPBasicAuth
logging.basicConfig(level=logging.DEBUG)
start_time = time.time()
def get_venmo_data(limit):
url = "https://venmo.com/api/v5/public?limit={}"
for i in range(50):
response = requests.get(url.format(limit))
response_dict = json.loads(response.text)
for transaction in response_dict["data"]:
print(unicode(transaction["message"]))
url = response_dict["paging"]["next"] + "&limit={}"
if __name__ == "__main__":
limit = 1
get_venmo_data(limit)
print("--- %s seconds ---" % (time.time() - start_time))keep-alive/persistent connections: 5번 돌린 결과 평균 7 초
거의 3배의 성능차가 보이기 때문에, keep-alive옵션을 적절히 활용하는게 성능에 좋아보인다.
Keep-alive와 proxy문제 : blind relays
서버와 클라이언트가 proxy없이 직접 통신할 경우에는 keep-alive 옵션이 정상 동작할 수 있지만, 만약 blind relay, 즉 keep-alive옵션을 지원하지 않는 proxy는 Connection header를 이해하지 못하고 그냥 extension header로 인식하는 경우에는 제대로 동작하지 않는다.
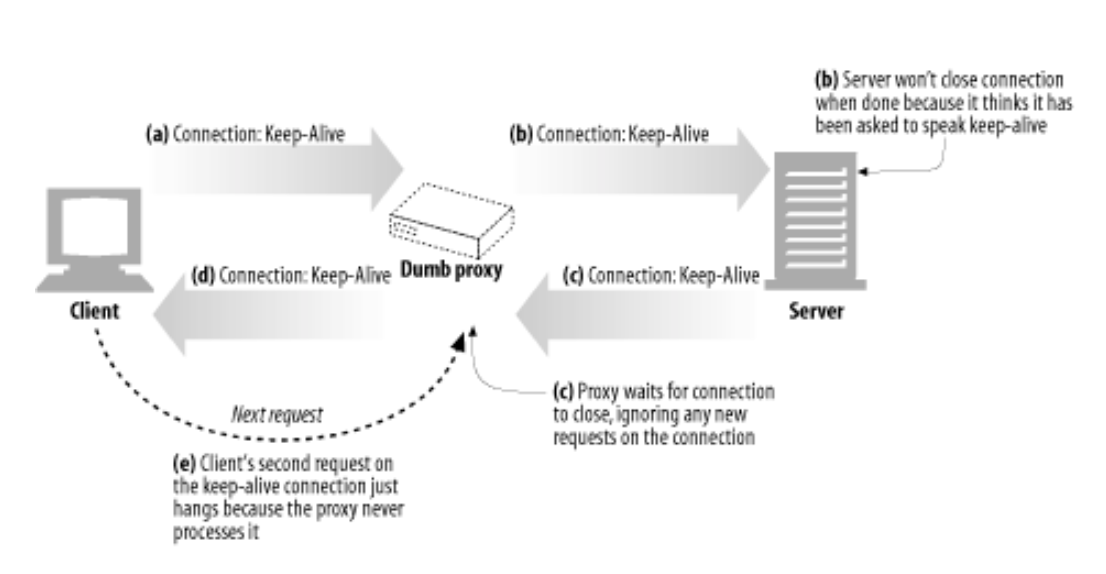
예를 들어 위 사진에서 (b)단계에 blind relay proxy가 server측에 HTTP Connection Keep Alive header를 보낼 경우에, 서버는 proxy가 keep-alive를 지원하는 걸로 착각하게 된다. 따라서 proxy와 헤더에 입력된 규칙으로 통신을 시도한다. 그리고 proxy는 서버가 보낸 header를 그대로 client에게 전달은 하지만 keep-alive옵션을 이해하지 못하기 때문에, client서버가 connection을 close하기를 대기한다. 하지만 client는 response에서 keep-alive 관련 헤더가 넘어왔기 때문에 persistent connection이 맺어진 줄 알고 close하지 않게된다. 따라서 이 때 proxy가 connection이 close될 때까지 hang걸리게 된다. 또한 client는 동일한 conenction에 request를 보내지만 proxy는 이미 close된 connection이기 때문에 해당 요청을 무시한다.이에 따라 client나 서버가 설정한 timeout이 발생할 때까지 hang이 발생한다.
따라서 HTTP/1.1부터는 proxy에서 Persistent Connection관련 header를 전달하지 않는다. persistent connection을 지원하는 proxy에서는 대안으로 Proxy Connection 헤더를 활용하여 proxy에서 자체적으로 keep-alive를 사용하는데, 이는 나중에 더 자세히 다루도록 하겠다.
Keep-alive의 대안 : HTTP/1.1
위에서 말한 HTTP/1.0의 문제를 해결하기 위해 HTTP/1.1부터는 다른 방식을 제공한다. 본 글의 주제는 아니기 때문에 간략하게만 다루도록 하겠다.
HTTP/1.1부터는 모든 connection에 대해서 별도의 설정이 있지 않으면 persistent connection을 맺는다. HTTP/1.1 어플리케이션들은 connection을 close하기 위해 명시적으로 Connection: close 헤더를 입력해야 한다.
Client는 별도로 Connection: close 헤더가 있지 않는한 서버가 응답한 뒤에 계속해서 재사용할 수 있다고 가정한다. 물론 별도로 보내지 않더라도 서버나 클라이언트측에서 connection을 종료할 수는 있다.
HTTP/1.1의 persistent connecion관련 규칙들
1) 클라이언트 측에서 Connection: close 헤더를 보낸 뒤에는 해당 커넥션을 재 사용할 수 없다.
2) 클라이언트가 더이상 connection을 재사용하고 싶지 않을 경우에는 Connection: close 헤더를 마지막 요청에 같이 보내야 한다.
3) connection이 계속해서 persistent하게 유지되기 위해서는 모든 요청에 오류가 없어야 한다. content-length가 다르다던지, encoding이 되지 않았다던지 하면 유지되지 않는다.
4) 클라이언트는 언제든 connection이 close될 수 있기 때문에 retry로직을 준비해두는게 바람직하다.

참고자료
https://www.oreilly.com/library/view/http-the-definitive/1565925092/ch04s05.html
https://www.imperva.com/learn/performance/http-keep-alive/
https://medium.com/@onufrienkos/keep-alive-connection-on-inter-service-http-requests-3f2de73ffa1