
쿼카러버의 기술 블로그
[블록체인] 분산 시스템과 블록체인 그리고 데이터 일관성(Consistency) 본문
분산 시스템과 블록체인 그리고 데이터 일관성(Consistency)

블록체인은 그 자체로 분산환경 시스템의 한 형태다. 일반적으로 분산 시스템이란 여러 컴퓨터가 네트워크를 통해 연결되어 작동하는 시스템을 말하기 때문이다. 그래서 블록체인과 데이터베이스 분산 처리에 대해 개발자 입장에서 공부하다보면 사실 기술적으로는 공통점이 정말 많을 수 밖에 없다. 누가 데이터를 다루고 보존하고 책임지냐의 문제에서만 차이가 있을뿐, 결국 성능 입장에서 직면하는 문제와 해결해야 하는 문제들 그리고 해결방법들은 서로 밀접하게 연결되어 있다. 탈중앙화 개념을 도입하기 위해 암호학기술, 난수 개념을 활용해서 좀 더 복잡한 메커니즘이 추가되는 정도..?
무튼 본 글은 백엔드 개발자 입장에서 매번 생각만하다 정리해봐야겠다 싶었던 다음 질문에 대한 답변을 해보면서 작성한 글이다.
블록체인(예: 이더리움)에서 각 노드들은 어떻게 모두 동일한 데이터(블록)를 유지할 수 있을까?
이 질문을 좀 더 장황하게 써보자. 블록체인의 본질인 분산 환경에서는 어떤 노드는 실수로 꺼질 수도 있고, 어떤 노드는 네트워크 연결이 불안정해 데이터를 전달받지 못할 수도 있을텐데, 어떻게 다양한 요소들을 극복하면서 일관되고 정확한 데이터를 유지할 수 있는 걸까? 참고로 여기서 말한 일관된 데이터는 블록 내의 트랜잭션 실행 순서 등이 어떻게 동일하게 유지되는가를 의미한다.
사실 이 질문은 블록체인에서 뿐만 아니라 점점 대중화되고 있는 분산 데이터베이스 시스템에서도 핵심인 consistency와 consensus의 개념에 대한 질문이다. 분산 시스템에서는 여러 노드가 함께 작동할 때 하나의 노드에서 문제가 발생하더라도 시스템 전체의 동작에는 영향을 미치지 않아야 한다. 여기서 말하는 정상 동작의 범주에 consistency는 필수적이다. consistency는 computer science분야에서 매우 중요하면서도 복잡하고 깊은 개념이기 때문에 이 글 하나로 이를 모두 다룰 수는 없다. 따라서 본 글에서는 다음의 소기의 목적을 달성해보려고 한다.
(1) consistency에 대한 개념 간단 설명
(2) 일반적인 분산 데이터베이스 시스템이 consistency를 유지하는 방법 간단 설명
(3) 이더리움이 트랜잭션을 처리하면서 블록을 생성하는 방법(consensus mechanism)
(4) 블록체인과 일반적으로 분산 시스템을 바라보는 관점의 차이
자 시작해보자!

Consistency
Consistency는 분산환경 시스템에서 가장 중요한 요소 중 하나다. Consistency에 대한 구체적인 설명을 더해보면 데이터가 접근되고 수정될 때 항상 정확하고 최신의 데이터가 유지되는 것을 의미한다. 예를 들어 두 명의 유저가 동일한 데이터를 동시에 접근했을 때 모두 같은 데이터를 볼 수 있어야하고, 한 명의 유저가 데이터를 수정했을 때 다른 유저는 수정된 최신의 데이터를 볼 수 있어야 한다.
서비스를 이용하는 입장에서는 어찌보면 당연히 보장돼야 하는 것 처럼 보이는 속성이다. 물론 한 대의 서버에서 동작할 때는 consistency를 보장하는 것은 비교적 쉬울 수 있다. 한 컴퓨터 내에서만 순서를 보장하면 되기 때문이다. 하지만 문제는 물리적으로 분산되어 있는 여러 대의 컴퓨터가 하나의 데이터베이스로 인식되어 동작해야 할 때다. 네트워크가 항상 안정적일 수는 없는 물리적 환경으로 인해 어쩔 수 없이 발생하는 한계점들이 존재하기 때문이다. 네트워크 장애가 절대 발생하지 않는 시스템을 구축하는 것은 물리적으로 불가능하다.
Consistency가 중요한 이유는 데이터 무결성을 보장하는데 있다. 데이터 무결성(data integrity)이란 정보가 정확하고 완전하며 안전하게 보호되어야 함을 의미한다. 여러 서비스의 예를 들어 데이터 무결성의 중요성을 설명해보겠다.
(1) 온라인 쇼핑몰 : 상품의 재고 정보는 구매자가 주문을 결정하는데 중요한 정보임
(2) 소셜 미디어 서비스 : 사용자가 게시물을 업로드 했는데, 일부 사용자에게는 게시물이 보이지 않거나, 댓글 좋아요 등의 활동이 일관되게 반영돼야 함
(3) 금융 서비스 예시 : 사용자가 자신의 계좌를 확인할 때 일관된 계좌 잔액을 보여주어야 함
(4) 블록체인 예시 : 특정 EOA(주소)이 잔액이나 트랜잭션 내역등의 정보가 모든 노드에서 일관되게 보여져야 함.
분산 데이터베이스 시스템이 Consistency를 지키는 방법
분산 데이터베이스가 consistency를 지키는 방법에 대해 이해하기 위해서는 먼저 CAP 이론에 대한 이해가 필요하다. CAP이론의 앞글자인 C가 Consistency를 의미한다.
데이터베이스 종류마다 Consistency를 유지하기 위해 사용하는 메커니즘과 알고리즘에는 어느정도 차이가 있을 수 있지만 기본적으로 Consistency를 지키기 위해서는 network partition 문제가 발생했을 때 non-consistent한 노드는 network partition 문제가 해결될 때까지 unavailable한 상태가된다. 이에 대해서는 CAP 이론 정리에서 따로 다루었으니 참고하길 바란다.
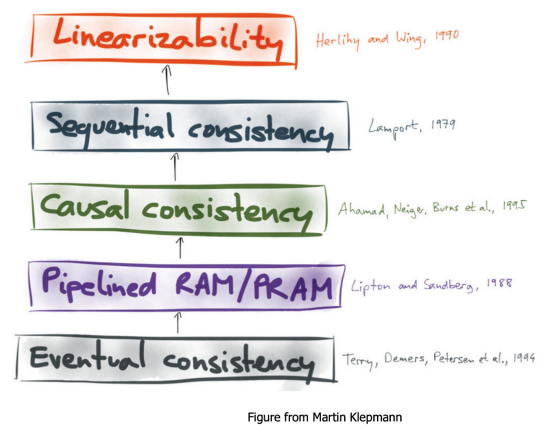
추가적으로 딥다이브해보고 싶다면 linearizability, sequential consistency, causal consistency, eventual consistency, quorum Consistency, consistent hashing, replication, sharding 이 키워드들을 공부해보는 것을 추천한다.
블록체인(이더리움)이 Consistency를 유지하는 방법
서론이 길었다. 블록체인은 연결된 여러 노드들 간의 데이터의 consistency를 유지하기 위해서 다양한 consensus mechanism 기술을 활용한다. 네트워크 종류마다 다 다르기 때문에 본 글에서는 가장 메이저 체인 중 하나인 이더리움에 집중해서 작성해보겠다.

블록체인 서비스를 개발하면서 사실 가장 헷갈렸던 부분은 P2P형태로 동작하고 있는 Geth(노드)에 트랜잭션 실행을 요청했을 때 트랜잭션이 여러 노드들에게 전파되는 타이밍이 다 다를텐데, 어떻게 하나의 블록으로 종합돼서 동일한 블록 내용으로 모든 노드들에게 전파되는지에 대한 부분이었다.
이더리움의 경우에는 기본적으로 많이 들어봤을 PoS(Proof of Stake)방식으로 consistency를 유지한다고 하는데, 사실 나는 PoS라는 개념보다는 개발자 입장에서 어떻게 데이터의 일관성을 유지하는지, 그리고 이를 위해 구체적으로 어떻게 동작하는지가 궁금했다. 처음 조사를 할 때는 블록체인은 기존 분산 시스템과는 다른 방법을 채택하고 있지는 않을까 하는 기대감에 공부를 해봤다. (현업에서 새로운 아이디어를 얻을 수 있을지도? 라는 기대감)
즉 내가 가장 궁금한 부분은 트랜잭션이 블록에 담기는 과정이다. 여러 노드들에게 각각 다른 트랜잭션 실행이 요청될텐데, 이 트랜잭션들이 실행되고 블록의 생성까지의 절차는 아래와 같다.
- 사용자는 실행하고자 하는 트랜잭션을 생성하고 비밀키로 서명한다.
- 서명된 트랜잭션은 JSON-RPC API를 사용해 노드에 요청한다. 이 때 사용자는 validator에게 수수료로 얼만큼의 가스비를 지불할지 정한다.
- 트랜잭션은 Ethereum의 execution client에게 전달된다. execution client란 유효성을 검증하는 client를 의미한다. sender가 충분한 ETH를 소유하고 있는지, 그리고 매칭되는 비밀키로 서명됐는지 등을 확인한다.
- 만약 트랜잭션 요청이 유효하다면 execution client는 local mempool(pending transaction 리스트)에 해당 트랜잭션을 추가하면서 동시에 gossip network를 통해 다른 노드들에게 트랜잭션을 전파한다.
- 이 때 transaction을 전파받은 다른 노드들 또한 자신의 local mempool에 해당 트랜잭션을 추가한다.
- RANDAO(randomness를 위한 메커니즘)를 통해 pseduo-randomly 선택된 네트워크상 하나의 노드는 현재 slot에 대한 block propser가 된다. 이렇게 선출된 노드는 다음 블록을 생성하고 전파하면서 동시에 이더리움 블록체인에 추가되고 global state을 변경시키는 역할을 담당한다.
- 참고로 이더리움 node는 크게 세가지 client를 내재하고 있다.
exectuion client: local mempool에 있는 트랜잭션들을 execution payload로 bundling하고, local에서 state change를 위해 해당 트랜잭션들을 실행해본다.consensus client: execution client가 local에서 실행한 트랜잭션 정보를 전달받아 execution paylaod가 beacon block의 한 부분으로 래핑된다. beacon block은 보상, 패널티 slashing, attesation등과 같은 정보들을 담고 있고, 이 beacon block을 통해 모든 네트워크가 해당 block의 sequence에 합의한다. Connecting the Consensus and Execution Clients.validator client
- 참고로 consensus client와 execution client는 parallel하게 실행된다. 이 둘은 아래 두 가지 작업을 수행하기 위해 항상 연결돼 있어야 한다.
- consensus client가 execution client에게 instruction을 제공
- execution client는 trnasanction bundle을 consensus client에게 전달하면 이를 beacon block에 포함시킨다.
- 참고로 이더리움 node는 크게 세가지 client를 내재하고 있다.
- 다른 노들은 이렇게 생성된 새로운 beacon block을 consensus layer gossip network를 통해 전달받는다. 그리고 execution client에게 전달해서 다시 로컬에서 실행해보면서 해당 beacon block내 트랜잭션들이 valid한지 재확인한다.
- validator client는 해당 블록 내 트랜잭션들이 유효한지 입증하고나서 다음 block으로 추가될 수 있는지 확인한다.
- 해당 블록은 각 노드의 local database에 추가된다.
- 이렇게 되고나서 transaction은 모두 finalize가 돼야한다. finalize됐다 함은 다시 revert될 수 없다는 것을 의미한다.
- 체크포인트는 각 epcoh마다 실행되며 supermajority link를 가지기 위해서는 모든 네트워크 상의 스테이킹된 66%의 ETH를 가진 노드들에 의해 인증되어야 한다.
무튼 블록 내의 트랜잭션의 순서가 결정되는 방식을 추가로 설명하자면 우선 block proposer로 선정된 validator가 트랜잭션의 순서를 결정한다. 그리고 block proposer는 아래 두가지 정보를 활용해 순서를 결정한다.
(1) gas price : gas price가 높을 수록 먼저 처리해줌
(2) nonce : 하나의 account에서 실행되는 트랜잭션 순서를 보장하기 위해 활용
절차를 이해하고보니 역시 블록체인이 consistency를 보장하기 위해 부리는 마법은 없었다. 결국 분산 시스템의 한 형태이기 때문에, 분산 처리 시스템이 활용하고 있는 leader selection 등 기술을 활용하고 거기에 작업에 반복성을 더해 consistency를 유지고하고 있을 뿐이었다.
블록체인과 일반적으로 분산 시스템을 바라보는 관점의 차이
사실 블록체인은 작업의 효율성(성능)을 희생하는 대신 작업 결과에 대한 신뢰도를 높인 시스템이다. 이는 일반적인 분산 시스템을 활용하는 목적과는 차이가 있다.
일반적으로 분산 시스템의 목적은 여러 서버가 일을 나눠서 처리함으로써 작업의 효율성을 높이거나 서비스의 가용성을 높이는 것을 목적으로 하고 있다. 하지만 분산 시스템의 한 종류인 블록체인은 분산시스템의 극단적인 한 형태로 여러 서버가 일을 분산해 처리하는 것이 아니라 동일한 일을 중복해서 처리한다. 즉 데이터베이스 분산 처리의 목적과는 다르게 성능보다는 신뢰도를 높이기 위해 설계된 아예 다른 아키텍처라고 생각해야 한다.
예를 들어 위에서 설명한 트랜잭션이 블록에 담기는 절차를 보면 노드들마다 모두 각자 local mempool에 트랜잭션을 담기도 하고, block proposer에 의해 전달된 block내 트랜잭션들을 모든 노드가 각자 다시 로컬에서 실행해보면서 트랜잭션이 valid한지 재확인한다. 그렇다. 더 많은 자원과 시간을 투입해서 일을 중복해서해야 하기 때문에 사실 블록체인의 성능은 분산시스템 입장에서 보았을 때 극도로 저하된다. 하지만 모든 노드가 일을 반복하고, 결과가 일치해야지만 블록이 인정되기 때문에 중앙화된 시스템 없이도 신뢰를 보장하는 것이다.
다시 정리해보면 분산 시스템은 일반적으로 중앙 컴퓨터의 과부하를 줄이고 하나의 일을 여러 컴퓨터가 처리하도록 함으로써 연산 성능, 가용성, fault tolerance 등을 얻기 위해 고안된 아키텍처로 많이 알려져 있다. 하지만 블록체인은 작업을 반복해서 효율성을 포기하는 대신 중앙화된 authority가 없어도 신뢰할 수 있는 데이터를 유지하는 방법을 연구하는 분야다.
물론 이렇게 방향성에 명확한 차이가 있기는 하지만, 신뢰성을 확보하면서도 블록체인의 성능을 높이려는 여러 가지 노력과 새로운 기술들이 제안되고 있고, 이를 같이 공부하다보면 분산 시스템 기술 발전에도 많은 도움이 된다고 생각한다. 따라서 현업에서 블록체인을 다루지 않더라도 블록체인 기술에 대해 흥미를 가지고 공부하다보면 분명 업무에 도움이 될 거라고 생각한다. 나도 블록체인을 계속해서 놓지 않고 공부하는 이유 중 하나다.

참고 자료 :
https://www.cs.ucr.edu/~nael/cs202/lectures/lec19.pdf
System Design 101 - Consistency
https://www.preethikasireddy.com/post/how-does-ethereum-work-anyway
https://medium.com/@thisisananth/consistency-consensus-8cd893a47f08
https://ethereum.org/en/developers/docs/consensus-mechanisms/
'분산 시스템' 카테고리의 다른 글
| [분산 시스템] CAP 이론 제대로 이해하기 (CAP Theorem) (CAP에 대한 오해를 풀어보자) (1) | 2023.04.19 |
|---|
