
쿼카러버의 기술 블로그
[Prometheus] 메트릭 종류 및 예시 정리 본문

앞 글에서 prometheus의 기본 개념에 대해 알아보았다. 이미 솔루션들에서 제공해주는 exporter이 있는 경우에는 왠만하면 exporter에서 제공해주는 정보만으로 모니터링이 가능하지만, 직접 웹 어플리케이션을 동작하고, 이 어플리케이션에 대한 모니터링을 수행해야 하는 등의 경우에는 custom exporter를 구현해야한다.
기본으로 제공되는 exporter들을 활용할 때도 물론이지만, custom exporter를 구현하기 위해서는 prometheus에서 수집하고 있는 메트릭이 어떤 종류가 있는지에 대해 알아둘 필요가 있다. 따라서 본 글에서는 프로메테우스에서 수집할 수 있는 메트릭의 종류들에 대해 알아보고자 한다.
메트릭 종류
프로메테우스에서 제공하는 메트릭 종류는 크게 아래와 같다.
(1) Counter
(2) Gauge
(3) Summary
(4) Histogram
이제 각각이 무엇인지에 대해 간단하게 알아보자
Counter
카운터는 cumulative metric으로, 값의 증가만 필요한 수치를 측정할 때 사용한다. 초기값은 0에서 시작되고, 값을 리셋하거나 증가만 할 수 있다. 예를 들어 request의 수, error발생 횟수 등 감소하지않는 특성을 가지는 대상에 대해 메트릭을 수집할 때 사용된다. 참고로 Counter는 정수 뿐 아니라 non-negative floating point value도 더할 수 있다.
예를 들어보자 만약 아래와 같이 add_product라는 API의 호출수가 측정됐다고 해보자.
# HELP http_requests_total Total number of http api requests
# TYPE http_requests_total counter
http_requests_total{api="add_product"} 4633433위 값이 의미하는 바는 해당 API가 서비스 시작 혹은 reset된 시점 이후부터 4,633,433회만큼 호출됐다는 것을 의미한다. 하지만 이런 절대값으로는 유의미한 정보를 얻을 수 없다. 예를 들어 지금 초당 몇개의 request가 들어오는지 확인하는 등의 작업이 필요하다. 그래야 모니터링 관련 알람을 설정하는 등의 작업이 가능하기 때문이다.
프로메테우스에서는 아래의 함수들을 활용해서 counter값을 처리한다. (irate등 더 있지만 나중에 다룰 예정)
rate() : timeseries로 저장된 메트릭들을 가지고 범위 시간 안에서의 초당 평균 호출량을 리턴한다.
예를 들어 1분 동안 호출이 60번 되었다면 rate함수를 호출시 아래와 같은 값을 리턴한다
rate(http_request_count_total[1m]) 1increase() : 특정 시간동안 카운터가 증가한 총 값을 리턴한다. rps/tps를 측정하고 싶을 때는 rate()을 사용하면 되지만, 실제 호출 횟수를 그래프로 그리고 싶을 때는 increase를 사용한다.
예를 들어 1분동안 60번 호출되었다면, increase를 아래와 같이 호출시 아래와 같은 값을 리턴한다.
increase(http_request_count_total[1m]) 60이는 최근 1분동안 들어온 요청 수를 의미한다.
물론 위 값은 아래와 같이 rate()만을 활용해서도 계산할 수 있다.
rate(http_request_count_total[1m]) * 60 resets(): 카운터가 얼마나 자주 reset()됐었는지 확인할 수 있다. 디버깅할 때 주로 사용한다.
요청 수 외에도 e-commerce의 경우에는 주문 수, 네트워크 인터페이스라면 number of bytes sent, received 와 같은 정보들을 측정하는데 counter가 사용된다. 참고로 counter는 reset이 가능하다는 점은 유의하고 사용하는게 안전하다.
Snippet
Python prometheus library에서 counter metric을 추가하는 snippet은 아래와 같다.
from prometheus_client import Counter
api_requests_counter = Counter(
'http_requests_total',
'Total number of http api requests',
['api']
)
api_requests_counter.labels(api='add_product').inc()Gauge
Gauge는 증가/감소가 가능한 값을 측정할 때 사용하는 metric이다. Counter와 다르게 값을 증가시키거나 감소시킬 수 있다. 예를 들어 현재 온도, 메모리 사용량, 커넥션 수, 떠 있는 pod수 등 갯수를 세야 하는 메트릭의 경우 Gauge를 사용한다. 다시 말해 scrape하는 순간의 value를 수집하는 것이다. Counter처럼 reset 혹은 이동평균이 적용되지는 않는다.
예를 들어 특정 호스트의 메모리 사용량을 측정하고 싶을 때는 아래와 같은 gauge metric이 리턴된다.
# HELP node_memory_used_bytes Total memory used in the node in bytes
# TYPE node_memory_used_bytes gauge
node_memory_used_bytes{hostname="host1.domain.com"} 943348382위 예시는 host1.domain.com 가 동작하고 있는 node가 metric을 수집당했을 때의 메모리 사용량이 약 900MB라는 뜻이다.
Gauge는 Counter와는 다르게 rate이나 increase같은 함수가 필요 없다. 하지만 평균, 최대값, 최솟값, percentile과 같은 계산은 때론 필요할 수 있다. 이때 사용하는 함수들로는 avg_over_time , max_over_time , min_over_time , quantile_over_time 가 있다.
하나만 예를 들어보자. host1.domain.com 노드의 10분 동안의 평균 메모리 사용량을 측정하고 싶으면 아래와 같이 query를 보낼 수 있다.
avg_over_time(node_memory_used_bytes{hostname="host1.domain.com"}[10m])Counter는 inc()만 있는 반면 Gauge는 inc, dec, set 함수를 모두 제공한다. 뿐만 아니라 고맙게도 client library에서 thread safety를 고려해 구현됐기 때문에 자유롭게 사용하면 된다.
Snippet
Python prometheus library에서 gauge metric을 추가하는 snippet은 아래와 같다.
from prometheus_client import Gauge
memory_used = Gauge(
'node_memory_used_bytes',
'Total memory used in the node in bytes',
['hostname']
)
memory_used.labels(hostname='host1.domain.com').set(943348382)Summary, Histogram
Summary 혹은 Histogram은 여러 개의 시계열 데이터를 생성할 뿐이라, 이 두 메트릭을 올바르게 사용하는 것도 매우 까다롭다. 따라서 Summary와 Histogram을 사용하기 위해서는 이 둘의 동작방식이 어떻게 되는지, 그리고 이들을 통해 얻을 수 있는 메트릭 값이 가지는 의미가 무엇인지 제대로 이해할 필요가 있다.
먼저 Histogram과 Summary는 observation들을 샘플링한다. 특히 request duration이나 response size같은 값들을 샘플링한다. 그리고 _sum과 _count으로 표현되는두가지 값을 계속해서 추적한다. _count 는 1번 observe될 때마다 1씩 increment되는, observation 횟수를 의미하고, _sum은 측정된 메트릭 값들의 총합을 의미한다.
참고로 Histogram과 Summary는 온도와 같은 negative 값들도 처리가 가능하다. 하지만 이들이 섞일 경우에는 rate()과 같은 함수를 사용할 수 없다. 따라서 만약 rate()을 사용하고 싶을 경우에는 두 개의 메트릭을 만들어서, 하나는 positive, 하나는 negative 값들만 담도록 해야 한다.
이 둘이 비슷한 특성을 가지고 있어서, 공통적인 부분을 적어보았고, 이제 각각이 어떻게 계산되는지 알아보자.
Histogram
Histogram은 측정치들의 분포를 보고자 할 때 매우 유용하다. 주로 request duration이나 response size를 측정할 때 사용된다. 예를 들어 내가 속한 회사의 SLO가 95%의 request를 300ms 미만으로 처리해주는 거라고 한다거나 할때 이를 계산하는데 Histogram을 활용할 수 있다. Histogram은 여러개의 호스트/pod에서 동일한 어플리케이션을 실행시키고 있을 때, aggregate도 가능해서 SLO를 위한 메트릭 측정에 매우 유용하다.
히스토그램은 측정치의 범위를 bucket이라는 일련의 간격으로 나누어 각 특정 bucket의 범위 내에 들어가는 측정값들을 count하는 식으로 계산한다.
Histogram 메트릭은 주로 특정 event의 size, response latency 등과 같은 메트릭 대상을 Observe라는 메소드를 통해 측정한다.
Histogram 메트릭은 아래 정보들로 구성돼 있다.
(1) _count : 1번 observe될 때마다 1씩 increment되는, observation 횟수를 의미한다.
(2) _sum : 측정된 메트릭 값들의 총합을 의미한다.
(3) le : 히스토그램의 bucket들은 counter 값을 가지고 있다. 그리고 각 bucket의 upper-bound 범위를 le 값으로 표현한다. 무슨 말이냐면 le=0.9라면, 0.9이하의 모든 observation 카운터 값을 의미한다.
예를 한번 들어보자
# HELP http_request_duration_seconds Api requests response time in seconds
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_sum{api="add_product" instance="host1.domain.com"} 8953.332
http_request_duration_seconds_count{api="add_product" instance="host1.domain.com"} 27892
http_request_duration_seconds_bucket{api="add_product" instance="host1.domain.com" le="0"}
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.01"} 0
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.025"} 8
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.05"} 1672
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.1"} 8954
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.25"} 14251
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="0.5"} 24101
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="1"} 26351
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="2.5"} 27534
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="5"} 27814
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="10"} 27881
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="25"} 27890
http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com", le="+Inf"} 27892위 예시는 _sum, _count그리고 12개의 bucket에 대한 값을 리턴하고 있다.
위 정보를 활용해서 PromQL에서 최근 5분 동안 평균 duration을 보고 싶다면 아래와 같이 쿼리를 보내면 된다.
rate(http_request_duration_seconds_sum{api="add_product", instance="host1.domain.com"}[5m]) / rate(http_request_duration_seconds_count{api="add_product", instance="host1.domain.com"}[5m])Histogram을 사용하면 query time에서의 percentile또한 구할 수 있다. 이 때 사용하는게 바로 histogram_quantile함수다. quantile과 percentile은 본질적으론 같지만 quantile을 사용하면 0에서 1까지의 범위 실수 범위 내로 설정할 수 있다.
예를 들어 host1.domain.com에서 동작중인 add_proudct API의 99th percentile 응답시간을 보고 싶으면 아래처럼 조회할 수 있다.
histogram_quantile(0.99, rate(http_request_duration_seconds_bucket{api="add_product", instance="host1.domain.com"}[5m]))Histogram의 단점
(1) bucket을 사전에 정의해야 한다. 만약 bucket을 제대로 설계하지 않으면 불필요하게 계산하게 되어 리소스를 낭비할 수 있고, 원하는 분위수를 얻지 못할 수 있다. 예를 들어 항상 1초 이상 응답시간을 가지는 API에 대한 메트릭틀 측정하는데 le를 1초 안으로 설정할 경우 해당 메트릭은 쓸모가 없어진다. 반대로 99.9%의 요청이 50ms안으로 리턴되는데 le바운드를 100ms로 설정하면 성능 측정에 큰 도움이 되지 않는다.
(2) 추정치가 리턴되기 때문에 정확한 percentile이 아니다. 물론 추정값으로 충분한 경우엔 상관 없다.
(3) server-side에서 계산되기 때문에, 데이터가 너무 많은 경우 서버에 부하가 심해질 수 있다.
Snippet
Python prometheus library에서 summary metric을 추가하는 snippet은 아래와 같다.
from prometheus_client import Histogram
api_request_duration = Histogram(
name='http_request_duration_seconds',
documentation='Api requests response time in seconds',
labelnames=['api', 'instance'],
buckets=(0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1, 2.5, 5, 10, 25 )
)
api_request_duration.labels(
api='add_product',
instance='host1.domain.com'
).observe(0.3672)Summary
Summary는 Histogram과 매우 유사한 메트릭이다. Summary는 Counter와 Gauge의 조합으로 이루어져 있다. 메트릭을 위해 두 개의 Counter와 옵셔널하게 Gauge를 사용한다. Summary는 Observe 메서드를 사용해 request duration, response size와 같은 대상을 측정하는데 주로 사용된다. 하지만 Histogram과는 다르게 여러 호스트들에 대한 aggregate이 불가능하다.
Summary는 아래와 같은 값을 측정 후 리턴한다.
(1) _count 는 1번 observe될 때마다 1씩 increment된다.
(2) _sum은 측정된 메트릭 값들의 총합이다.
(3) 옵셔널하게 quantile label이 붙은 gauge가 값이 같이 리턴된다. 참고로 prometheus client는 sliding time window로 streamd quantile을 값을 제공하고 있다.
- quantile이 무엇을 의미하는지는 아래에 appendix에서 설명한다.
Summary 메트릭을 이해하기 위해서는 예시를 볼 필요가 있다.
# HELP http_request_duration_seconds Api requests response time in seconds
# TYPE http_request_duration_seconds summary
http_request_duration_seconds_sum{api="add_product" instance="host1.domain.com"} 8953.332
http_request_duration_seconds_count{api="add_product" instance="host1.domain.com"} 27892
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0"}
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0.5"} 0.232227334
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0.90"} 0.821139321
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0.95"} 1.528948804
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="0.99"} 2.829188272
http_request_duration_seconds{api="add_product" instance="host1.domain.com" quantile="1"} 34.283829292위에서 볼 수 있듯, 히스토그램과 동일하게 _sum과 _count값이 있다. 위 예시는 거의 십억단위 갯수의 observation이 있었고, 1.6백만 초가 걸렸던 것으로 보여진다.
또한 Quantile=0의 경우 add_product_API의 response time 중 최소값을 의미하며 Quantile=1은 최대값을 리턴한다. Quaintile=0.5는 중앙값(median), 0.9, 0.95, 0.99는 90th, 95th, 99th percentile을 의미한다.
이제 Summary를 활용하는 다른 예시도 한번 보자
Summary는 Counter를 가지고 있기 때문에 rate()를 활용해 원하는 표준값을 만들어낼 수 있다.
rate(prometheus_rule_evaluation_duration_seconds_count[5m])위처럼 5분 동안 평균적으로 초당 몇 회의 observation이 있었는지 볼 수 있다.
rate(prometheus_rule_evaluation_duration_seconds_sum[5m])위처럼 5분 동안 observation이 초당 얼마나 걸렸는지 확인할 수 있다.
위 두 값을 활용해서 아래와 같이 한 observation당 duration이 얼마나 되는지도 확인할 수 있다.
rate(prometheus_rule_evaluation_duration_seconds_sum[5m]
/
rate(prometheus_rule_evaluation_duration_seconds_count[5m])즉 Summary를 활용하면 quantile없이도 우리는 latency, size of data transferred per request, record accessed와 같은 정보들을 얻을 수 있다.
Summary의 quantile의 단점
참고로 Summary는 Histogram보다는 더 정확한 quantile을 계산하지만 아래 3가지 단점이 있다.
(1) quantile 계산이 client-side에서 이루어지기 때문에 client에 부담을 줄 수 있다. client에서 sorted list를 계속 유지해야 하기 때문이다. client library에서 리소스 사용을 줄이기 위해 정렬해야 하는 데이터 수를 제한하기는 하지만 그에 따라 정확도도 떨어지게 된다. 참고로 모든 client library에서 quantile정보를 제공하지는 않는다.
(2) quantile값 또한 client에 의해 사전에 정의돼야 한다. 사전에 정의되지 않은 quantile값은 query를 통해 조회할 수 없다.
(3) 여러 인스턴스에서 동작하는 API들에 대한 aggregation이 불가능하다. 사실 이 부분이 제일 크리티컬하다. 예를 들어 add_product API가 10개의 호스트에서 동작하고 있다고 했을 때, 모든 호스트를 대상으로 aggregate할 수 없다. 각 host의 percentile만 확인할 수 있을 뿐이다. 따라서 이럴 때는 비슷하게나마 aggregate이 가능한 Histogram을 사용해야 한다.
Snippet
Python prometheus library에서 summary metric을 추가하는 snippet은 아래와 같다.
from prometheus_client import Summary
api_request_duration = Summary(
'http_request_duration_seconds',
'Api requests response time in seconds',
['api', 'instance']
)
api_request_duration.labels(api='add_product', instance='host1.domain.com').observe(0.3672)Appendix
Summary vs Histogram
참고로 Histogram과 Summary는 매우 비슷한 개념으로 동작하지만 주요 차이점을 하나 말해보자면, Summary는 streaming quantile 계산을 client side에서 계산하는 반면 Histogram은 버킷당 obeservation을 카운팅하고, 히스토그램 버킷의 분위수 계산은 server side에서 histogram_quantile 함수를 통해 계산된다는 점이다.
Histogram과 Summary의 차이를 요약한 테이블은 아래와 같다.
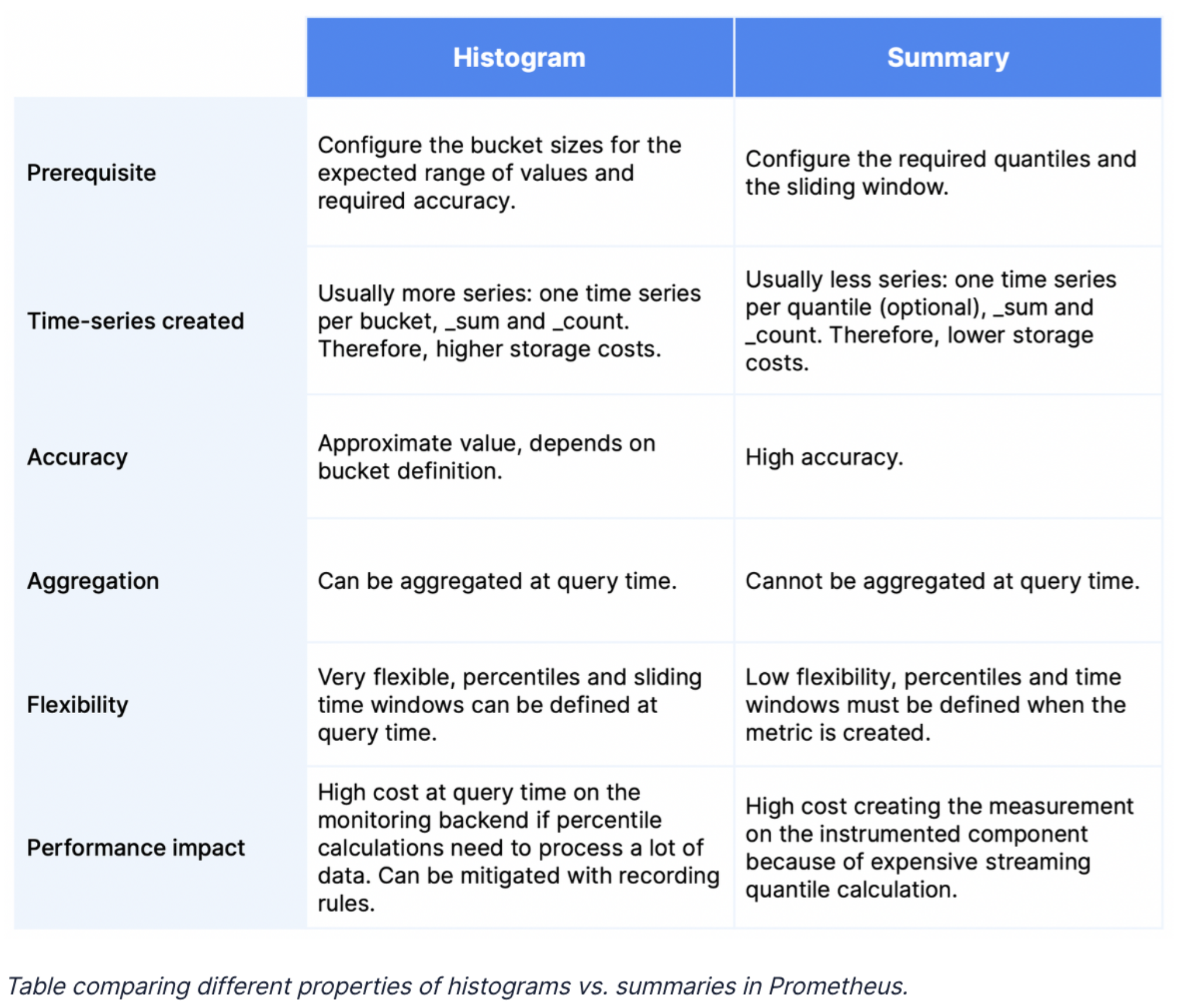
일반적으로 percentile은 필요 없고 계약상의 값만 추정이 필요한 경우를 제외하고는 histogram을 사용한다. histogram이 더 flexible하고 여러 인스턴스에 동작할 때 aggregate이 가능하기 때문이다.
quantile이란?
quantile(분위수) 개념에 대해 간단하게 알아보자.
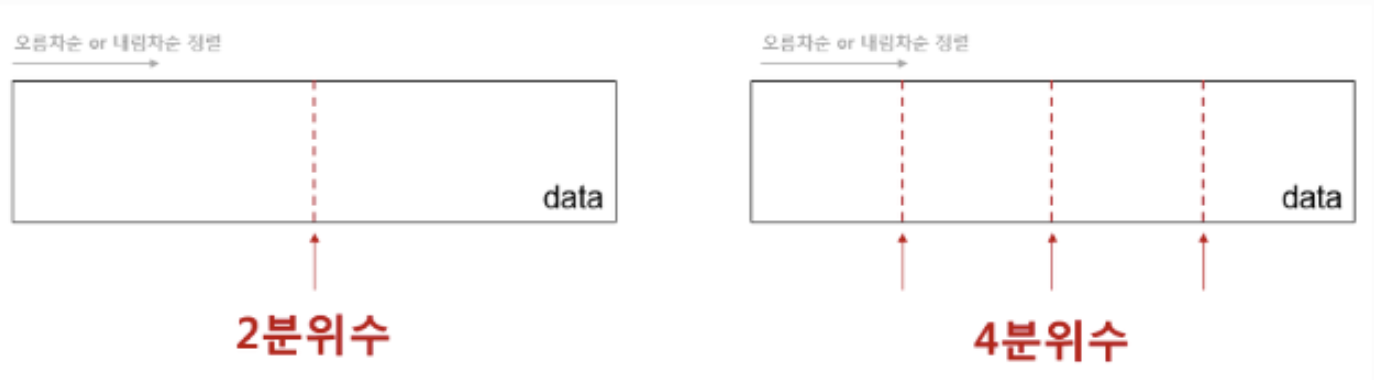
어떤 변수의 수많은 값들 중 '상위 ■■%'지점을 찾아야만 하는 경우에는 분위수를 사용한다.
즉, quantile(분위수)란 오름차순(혹은 내림차순)로 정렬되어 있는 전체 자료를 특정 개수로 나눌 때 그 기준이 되는 수를 말한다. 따라서 분위수 앞에는 자료를 몇 개로 나눌지 결정하는 숫자가 붙어있다. 예를 들어 2분위수는 자료 전체를 2등분 하는 수라서 2분위수가 된다. 전체를 q개로 나누기 위해 필요한 수의 개수는 q-1개다. 따라서 4분위수의 3개의 분위수는 일사분위수, 이사분위수, 삼사분위수라고 부른다.
이를 일반화해보면 Quantile은 주어진 데이터를 동등한 크기로 분할하는 지점을 말한다. 보통 kth q-quantile이란 표현을 쓰는데 이것은 X의 분포를 확률적으로 q개의 균등한 조각으로 잘랐을때 앞에서부터 k번째 조각까지의 위치를 얘기한다.
Prometheus에서는 10개의 분위수 객체들을 메모리에 적재시켜놓고 유지한다. 그리고 모든 obeservation이 발생할 때마다 10개의 객채 모두로 전송된 뒤 각각 다음 1분 부터 추적되고, 기록된지 10분을 넘긴 observation은 넘기면 해당 객체는 제거된 다음 empty한 분위수 객체를 새로 메모리에 적재해 측정한다. 다시 말해 프로메테우스에서 Summary를 통해 리턴되는 각 quantile은 지난 10분 동안의 observation에 대한 측정값이며, 1분 단위로 측정된다. 이렇게 하는 이유는 너무 예전 데이터로 인해 최근 observation들에 대한 정보가 사라지지 않게 하기 위함이다.
자 이렇게 프로메테우스의 메트릭에는 어떤것들이 있는지에 대해 알아봤다. 글 호응이 좋으면 프로메테우스를 직접 실행해보고 다뤄보는 튜토리얼 글도 작성해보도록 하겠다.

참고자료
https://www.robustperception.io/how-does-a-prometheus-counter-work/
https://www.robustperception.io/how-does-a-prometheus-gauge-work/
https://www.robustperception.io/how-does-a-prometheus-summary-work/
https://www.robustperception.io/how-does-a-prometheus-histogram-work/
https://hsm-edu.tistory.com/533
https://www.timescale.com/blog/four-types-prometheus-metrics-to-collect/
'[Infra & Server] > 데브옵스' 카테고리의 다른 글
| [k8s] 쿠버네티스에서의 리더 선출 (feat. 쿠버네티스, stateless) (0) | 2023.12.16 |
|---|---|
| [Prometheus] 프로메테우스 기본 개념 정리 (p.s. 메트릭이란?) (0) | 2022.10.01 |
| [Ansible] Ansible 시리즈 1탄 - Ansible 기본 개념 및 설치 튜토리얼 (2) | 2022.08.10 |
| [쿠버네티스] Helm이란? Helm 차트란? (11) | 2022.05.18 |
| [Github Action] Github Action 간단 시리즈 3탄 : Secret 및 Environment적용해보기 (0) | 2022.01.20 |



