
쿼카러버의 기술 블로그
[golang] profile 간단 이해(profiling, 프로파일링에 대하여) 본문
golang은 성능이 매우 중요한 경우 사용되는 언어 중 하나다. 따라서 코드가 최적화 된 것을 직접 확인하기 전에 그냥 가정만으로 최적화하는 방식으로는 사실 부족하다. 코드의 성능과 bottleneck에 대한 insight를 가지고 있어야 좀 더 효율적으로 최적화할 수 있는데, 이 때 활용하는 것이 바로 profiler다.
필자는 최근 맡고 있는 서비스의 성능테스트를 진행하면서 성능 개선을 위해 profiling을 진행해보았고 나름 성과도냈다(후후), 그리고 이왕 하는김에 내용을 좀 정리해보았다. 제목은 간단 이해라 했는데 사실 분량이 상당히 길다. 죄송..

본 글의 목적은 다음과 같다.
(1) profiling 기본 개념 이해 (긴글 주의)
(2) SVG 그래프 기본 개념 이해
이 글에선 이정도만 다루고 다음 글에서는 HTTP 서버를 프로파일링 하는 예제에 대해 살펴볼 예정이다.
profile이 뭔지 궁금하다면 아래 글을 한번 읽어보는 것을 추천한다!

profile이란?
프로파일(profile)은 프로그램의 어떤 얼마나 자주 그리고 얼마나 오랫동안 실행되었는지를 기술하는 통계 집합을 의미한다. 따라서 profiling이란 프로그램의 optimization technique 중 하나로, 프로그램이 어떻게 동작하는지 파악하기 위해 통계 수치를 활용하는 것을 의미한다. 여기서 말하는 통계 집합이란 CPU 사용량, memory allocation, time spent on program routine 등을 의미한다.
이쯤되면 profile과 benchmark의 차이가 궁금할 수 있다. Benchmark는 특정 함수의 runtime 정보를 수집한다면 profiling은 프로그램 전체의 동작에 대한 runtime 정보를 수집한다는데서 차이가 있다.
profiling을 하는 이유
Profiling은 프로그램에서 성능 저하가 발견됐을 때 왜 프로그램의 성능이 저하됐는지 확인하기 위해 진행한다. Benchmark는 특정 함수의 성능만을 파악할 수 있기 때문에, 이런 codebase의 통계 수치만으로는 성능저하의 원인을 다 파악하기에는 한계가 있다. 전체 그림을 보기 어렵기 때문이다.
또한 go는 앞서 말했듯 성능이 좋은 언어 중 하나지만 잘못 engineering된 프로그램은 go를 사용한다 해도 느리다. 따라서 engineering이 잘 됐는지 확인하기 위해서 profiling을 활용하는 것도 좋은 방법 중 하나다.
profiler란?
profiler란 앞서 설명했던 profile의 정의에서 유추할 수 있듯 성능 분석, 즉 프로그램의 시간 복잡도 및 공간, 특정 명령어 이용, 함수 호출의 주기와 빈도 등을 측정하는 동적 성능 분석 툴이다. profiler를 잘 활용하면 성능 이슈, 메모리 누수, thread contention 등과 같은 성능과 관련된 주요 측면들을 분석할 수 있다. 그리고 go-lang은 친절하게도, pprof라는 built-in 패키지로 profiler를 제공하고 있다.
profile의 종류
goroutine: 모든 고루틴들의 stack tracesCPU: runtime에 리턴되는 CPU의 stack tracesHeap: live 객체들의 memory allocation samplingAllocation: 모든 객체들의 memory allocation samplingThread: 새로운 OS thread의 생성과 관련된 stack tracesBlock: 동기화 primitives를 blocking한 stack tracesMutex: mutex holder들에 대한 stack traces
go를 활용한 간단한 profiling 실습
아래와 같은 프로그램을 작성하고 pprof API를 사용해 CPU profile을 한번 실행해보자.
package main
import (
"fmt"
"log"
"os"
"runtime/pprof"
)
func doSum() int {
sum := 0
for i := 0; i < 787766777; i++ {
sum += i
}
return sum
}
func main() {
f, err := os.Create("profile.pb.gz")
if err != nil {
log.Fatal(err)
}
err = pprof.StartCPUProfile(f)
if err != nil {
log.Fatal(err)
}
defer pprof.StopCPUProfile()
result := doSum()
fmt.Println(result)
}위와 같이 StartCPUProfile, StopCPUProfile을 호출해 프로파일링을 진행 후에 프로그램을 빌드하고
$ go build -o gettingstarted main.go해당 프로그램을 실행하고 나면 "profile.pb.gz” 라는 파일이 생성된다.
./gettingstarted그러고 생성된 파일에 대해 분석을 하기 위해서 아래 커맨드를 실행하면 cpu profiling에 대한 결과를 확인할 수 있다.
$ go tool pprof gettingstarted cpu.profile자 이제 맛보기로 go 프로그램의 프로파일링을 진행해 보았는데, 이를 어떻게 해석하는지에 대해서는 아직 설명하지 않았다. 지금부터 프로파일링을 제대로 이해하기 위해 알아야할 주요 개념들에 대해 알아보자
profiling에서 알아두어야 할 주요 개념
profile 파일 포맷 : protobuf
go에서 profiling을 하고 나서 생성되는 프로파일 파일은 protobuf 파일 포맷으로 작성된다. 이는 구글에서 개발한 자료구조로, 이를 읽기 위해서는 구글이 개발한 protoc을 설치해야 한다. protocol buffer를 간단히 설명하자면, structured data를 네트워크 전송에 더 유리한 lightweight format으로 serialization할 수 있는 자료구조다. JSON이나 XML같이 데이터의 필드명들이 serialize되지 않는다는 점에서 큰 차이가 있다. 따라서 serialize된 메시지를 읽기 위해서는 specification을 따라서 읽어야 한다. 여기서 말하는 specification이란 proto file인데, 더 자세한 얘기는 별도의 글에서 다루도록 하겠다.
사실 직접 pb 파일을 읽어야 하는 경우도 있겠지만, 필자의 경우는 callgrind나 pprof tool로 그래프를 그려서 확인하는 경우가 대부분이어서, 해당 과정에 대해서는 상세히 다루지 않겠다.
call stack
프로세스가 실행되면 함수 호출들은 stack에서 관리된다. 프로그램이 실행되면 함수 호출과 함께 시작되는데, main 함수가 가장 먼저 호출되고, 해당 main 함수가 다른 함수들을 호출하고 그 다른 함수가 또 다른 함수들을 호출한다. 그리고 이게 호출될 때마다 stack에 해당 함수 호출이 call stack에 쌓인다. 쉽게 정리하면 특정 프로그램의 call stack은 현재 실행되고 있는 함수들의 ordered list라고 생각하면 되겟다. 그리고 이 call stack을 읽기 위해 사용되는 패키지가 바로 debug 패키지다.
call stack을 아래 예제를 통해 간단하게 확인해보자. 다음 프로그램에서 함수들의 호출 순서를 보면 main → firstFunctionToBeCalled → secondFunctionToBeCalled → debug.PrintStack() 순으로 호출한다.
// profiling/stack/main.go
package main
import "runtime/debug"
func main() {
firstFunctionToBeCalled()
}
func firstFunctionToBeCalled(){
secondFunctionToBeCalled()
}
func secondFunctionToBeCalled(){
debug.PrintStack()
}그리고 위 프로그램을 실행해보면 아래처럼 main → debug.Stack까지 처음 부터 끝까지의 call stack을 출력할 수 있다. 그리고 profiler는 이 call stack을 parse한 정보를 활용해 프로그램을 측정한다.
$ go run main.go
goroutine 1 [running]:
runtime/debug.Stack(0xc00000e1b0, 0x1, 0x1)
/usr/local/go/src/runtime/debug/stack.go:24 +0xa7
runtime/debug.PrintStack()
/usr/local/go/src/runtime/debug/stack.go:16 +0x22
main.secondFunctionToBeCalled()
/Users/maximilienandile/go/src/go_book/profiling/stack/main.go:14 +0x20
main.firstFunctionToBeCalled()
/Users/maximilienandile/go/src/go_book/profiling/stack/main.go:10 +0x20
main.main()
/Users/maximilienandile/go/src/go_book/profiling/stack/main.go:6 +0x20CPU time
프로파일링 중에 하나인 CPU profile에 대해서 한번 이해해보자. 이 개념을 이해해야 CPU 프로파일링을 제대로 진행할 수 있다.
CPU time의 의미는 “the Central Processing Unit’s time (CPU) to execute the set of instructions defined in your program”를 의미한다. microprocessor가 프로그램에서 정의된 instruction들을 처리하게 될텐데, 프로그램이 복잡하면 복잡할 수록 더 많은 CPU Time이 필요해진다.
그리고 여기서 CPU time은 두개의 subcategory로 나눌 수 있다.
(1) CPU user time
(2) CPU system time
위 두가지 subcategory를 이해해보기 위해 아래 예제를 한번 보자
// profiling/understanding-CPU-profile/main.go
package main
import (
"fmt"
"log"
"os"
"runtime/pprof"
)
func main() {
// set CPU profiling (1)
f, err := os.Create("profile.pb.gz")
if err != nil {
log.Fatal(err)
}
err = pprof.StartCPUProfile(f)
if err != nil {
log.Fatal(err)
}
defer pprof.StopCPUProfile()
// CPU intensive operation (2)
test := 0
for i := 0; i < 1000000000; i++ {
test = i
}
fmt.Println(test)
}위 프로그램을 한번 실행해보자. 시간을 측정하기 위해 time utility를 사용했다. 참고로 time utility는 Mac과 Linux 유저면 사용할 수 있다
time ./main
real 0m0.629s
user 0m0.518s
sys 0m0.005s위 결과를 도식화 하면 아래와 같다.

- 0.629s : 프로그램을 invoke하고 종료되기까지 걸린 총 시간
- 0.518s : user의 CPU time으로, CPU가 kernel space가 아닌 user space에서 instruction들을 실행하는데 소요된 시간을 의미한다.
- 0.005s : system CPU time을 의미한다. kernel space에서의 명령어를 실행하는 시간을 의미한다. 예를 들어 open file 같은 시스템 콜들을 의미한다.
위 케이스에서는 CPU time에서 kernel space에서 차지하는 비중이 매우 적기 때문에 이번에는 syscall을 많이 일으키는 프로그램을 한번 돌려보자
// profiling/system-call/main.go
package main
import (
"fmt"
"io/ioutil"
"log"
"syscall"
"time"
)
func main() {
for i := 0; i < 100; i++ {
fileName := fmt.Sprintf("/tmp/file%d", time.Now().UnixNano())
err := ioutil.WriteFile(fileName, []byte("test"), 0644)
if err != nil {
log.Fatal(err)
}
err = syscall.Chmod(fileName, 0444)
if err != nil {
log.Fatal(err)
}
}
}ioutil.Writefile는 두 개의 syscall을 호출한다.openandwriteChmodsyscall을 호출한다.- 위처럼 호출하고 실행해보면
$ go build main.go
$ time ./main
real 0m0.031s
user 0m0.004s
sys 0m0.023s위 결과를 도식화 하면 아래와 같다.

이번에는 system time 쪽의 비중이 더 높은 것을 확인할 수 있다.
Sample
profile 파일을 decode해보면 많은 sample들을 볼 수 있는데, 여기서 말하는 sample이라는 개념이 좀 혼란스러울 수 있기 때문에 한번 정의해보자
profiling에서 말하는 sample은 profiling되는 특정 시간동안의 측정된 단위를 의미한다. 프로그램을 프로파일링 할 때 우리는 측정되는 여러가지 수치들이 모두 sample이라는 형태로 구성되어 저장된다. 예를 들어 아래와 같은 그림에서 3 개의 sample 예시를 보면

(1) a measure
(2) a location
(3) optional additional information
세 가지의 구성요소로 이루어져있다.
물론 measure는 측정되는 값을 의미하기 때문에 profile의 종류에 따라 다르다.
그리고 이 sample들이 생성되는 과정을 한번 알아보자. CPU profile인 경우에는 프로그램은 매 100ms마다 한번씩 stop된다. 그리고 profiler가 100ms 간격으로 프로그램을 멈출때마다 다음 작업을 수행한다.

(1) 데이터 수집
(2) 데이터를 파싱해서 measure를 추출
(3) sample 생성
위를 다시 한번 정리해보면 call stack에서 데이터를 수집해서, 각각 항목바다 CPU time을 측정 후 sample을 생성한다. 그리고 pprof tool을 사용하면 이 sample들을 시각화 할 수 있다. 예를 들어 아래와 같이 측정된 profile을 로딩하고 pprof interactive shell에서 traces를 호출하면 아래와 같이 확인할 수 있다.
$ go tool pprof main profile.pb.gz
File: main
Type: cpu
Time: Jan 13, 2019 at 7:07pm (CET)
Duration: 720.43ms, Total samples = 470ms (65.24%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
(pprof) traces
File: main
Type: cpu
Time: Jan 13, 2019 at 7:07pm (CET)
Duration: 720.43ms, Total samples = 470ms (65.24%)
-----------+-------------------------------------------------------
240ms main.main
runtime.main
-----------+-------------------------------------------------------
190ms main.main
runtime.main
-----------+-------------------------------------------------------
30ms runtime.nanotime
runtime.sysmon
runtime.mstart1
runtime.mstart
-----------+-------------------------------------------------------
10ms main.main
runtime.main
-----------+-------------------------------------------------------위 출력물에선 총 4개의 샘플이 있다. 그리고 첫번째 column은 sample의 값(measure)을 의미한다. 이 케이스에서는 CPU time이다. 그리고 second column은 trace 정보를 담고 있다.
위 출력물을 한번 자세히 분석해보면
- profiling을 build하는데 720.43ms만큼 걸렸고
- 측정된 sample들은 470ms를 소모했으며, 702.43중 65.24%가 소요됐다.
- 위에서 첫 번째 sample은 240ms of CPU time을 소요했다.
- 그리고 runtime.main 이 호출되고, main.main이 호출됐다는 것을 확인할 수 있다.
여기서 duration이라는 단어가 좀 헷갈릴 수 있는데, program의 duration을 의미하는게 아니라 profile duration을 의미한다. program의 total execution time은 profile duration보다 짧다. 이는 profiling은 program이 시작된 뒤에 시작되고, main function이 끝나고난 뒤에 끝나기 때문이다.
Flat and cumulative
위 출력물에서 flat과 cum이라는 두 개의 column이 있다.
flat은 profile을 진행할 때 특정 함수의 CPU time / 메모리 사용을 의미한다.
- 특정 함수인 것 주의 할 것.
cum은 해당 함수 뿐 아니라, 해당 함수를 호출한 stack을 모두 포함한 메모리사용을 의미한다.
예를 들어 아래 케이스에서는
A함수의 flat 값은 4고, cum은 11이 된다.
func A() {
B() // takes 1s
DO STH DIRECTLY // takes 4s
C() // takes 6s
}그리고 이 flat과 sum개념이 분석할 때 어떻게 씌이는지 한번 아래 예제를 통해 살펴보자. 다음은 CPU profile의 한 예고, flat, flat%, sum%, cum, cum%을 가지고 어떻게 분석할 수 있을지 한번 살펴보자

- 위에서 헷갈릴 수 있는 케이스를 한번 자세히 분석해보자
- 예를 들어 runtime.memmove가 flat으로 1.75s를 차지하고, total CPU time에서 58.72%를 차지한다고 해보자. → 제일 무거운 연산이라고 할 수 있음
- 그리고 sum%는 위에서 아래로 cumulative하게 더해져 가는 구조임
- 그리고 cum을 보면 이 함수 + 자신이 호출하는 함수들의 시간까지 다 포함해 1.75s임
- 그리고 전체 total total time에서 얼마나 차지하냐? 58.72% → flat쪽 %와 같은거로 봐서, 더 호출하는게 없나봄
getTurnover의 경우 전체 cum%는 96.64%를 차지하지만 flat은 0.13s고, 전체에서 4.36%밖에 차지하진 않음. 즉 얘가 호출하는 call stack에서 엄청 오래걸리는 뭔가가 있다라고 생각해볼 수 있다.
자 그럼 여기서 getTurnover에 대해서 좀 더 자세히 보고 싶을 수 있는데, 이 때 pprof의 interactive shell을 통해 좀 더 자세히 확인할 수 있다.
아래는 그냥 특정 프로그램을 프로파일링 했다는 전제하에 나오는 출력물을 어떻게 계산할 수 있는지에 대한 예시다.
(pprof) traces focus main.getTurnover-----------+-------------------------------------------------------
1.58s runtime.memmove
runtime.growslice
main.getTurnover
main.main
runtime.main
-----------+-------------------------------------------------------
70ms runtime.memclrNoHeapPointers
runtime.growslice
main.getTurnover
main.main
runtime.main
-----------+-------------------------------------------------------
20ms main.getTurnover
main.main
runtime.main
first stack trace
main.getTurnover는 callstack에서 3번째에 있고,main.main이 호출했으며, 이main.getTurnover는runtime.growslice를 호출를 했고, 이런식으로 아래에서 위로 제일 먼저 호출된 순으로 보여준다.- 그리고 이 sample에서는
getTurnover는runtime.grow가 return하기를 기다린다. - 따라서 우리는 이걸 cumulative duration으로 더하면된다.
second stack trace
- 마찬가지로
getTurnover이 같이 있고, 3번째 위치에 있음- cumulative duration으로 더하자
third call stack
getTurnover가 가장 위에 있음- flat duration으로 더하자
즉, getTurnover의 flat duration 20ms
cumulative time of main.getTurnover는 1.58+70ms로, 1.65s가 되겠다.
Dropped nodes
아래 실행화면을 한번 보자

위 output에서 dropped node라는 말이 있는데, 여기서 dropped node는 filtered out된 node들을 말한다. node는 object entry 혹은 tree안의 node를 의미하는데, 여기서 node를 dropping하는 이유는 노이즈를 제거하기 위함이다. 하지만 노이즈를 제거하다가 root cause를 잃게되는 경우도 있다.
- 만약 dropped node가 없이 분석하고 싶다면
nodefraction=0를 pprof 실행할 때 옵션으로 넣거나 pprof 쉘에서nodefraction=0을 입력하면된다.
Allocation과 Heap Profile의 차이
pprof tool이 allocation profile과 heap profile이냐는 garbage collected object를 보여주냐 안보여주냐 여부에 차이가 있다. Allocations profile은 앱이 시작될 때부터 allocate된 모든 객체들을 다 보여준다. 예를들어 garbage collected된 객체들도 포함한다. 하지만 Heap profile은 garbage collected bytes까지는 고려하지 않고 현재 live한 allocated object만 보여준다.
아래의 flag를 pprof interactive shell에 입력해서 heap과 allocations profile에서 모두 여러 모드를 출력하도록 할 수 있다.
inuse_space : 아직 release되지 않은 memory
inuse_objects : 아직 release되지 않은 객체들의 수
alloc_space : released여부와 관계없이 allocate된 메모리 총양
alloc_objects : released 여부와 관계없이 allocate된 객체들의 수
SVG Graph
top 명령어로 분석을 하는 방법도 있지만 좀 더 직관적인 insight를 얻기 위해서는 그래프를 보는 것도 도움이 된다. 따라서 svg graph를 그리고 보는 법에 대해서 한번 알아보자.
먼저 그래프를 그리고 보기 위해서는 다음이 설치돼야 한다
- Graphviz is available on homebrew for MacOS users :
brew install graphviz - For Linux users :
apt-get install graphviz
방법 1) http서버에 대한 프로파일링 진행할 경우
pprof에서는 profile를 SVG format으로 그려서 출력하도록 할 수 있다.
아래 커맨드를 사용하면 5초동안 CPU profile을 가져와서 SVG file을 띄워주는 브라우저를 실행한다.
pprof -svg http://localhost:8080/debug/pprof/profile?seconds=5- dot: Generates a report in .dot format. All other formats are generated from this one.
- svg: Generates a report in SVG format.
- web: Generates a report in SVG format on a temp file, and starts a web browser to view it.
- -png, -jpg, -gif, -pdf: Generates a report in these formats.
gif로 보고싶으면
pprof -gif http://localhost:8080/debug/pprof/profile?seconds=5방법 2) http서버에 대한 프로파일링 진행할 경우
pprof http://localhost:8080/debug/pprof/profile\?seconds\=20
(pprof) gif #사진으로 출력하고 싶을 때
(pprof) web #web으로 보고싶을 때이렇게 실행하면 pprof interactive shell이 켜지고 거기서 gif만 입력해도 gif를 만들어줌.
방법 3) profile 파일이 이미 있는 경우
pprof -raw -seconds 30 http://localhost:8080/debug/pprof/profile
#- 여기서 출력해주는 .pb.gz 파일 이름 받아다가
pprof -http=":9000" /Users/richetoh/pprof/pprof.samples.cpu.015.pb.gz
SVG 읽는 법
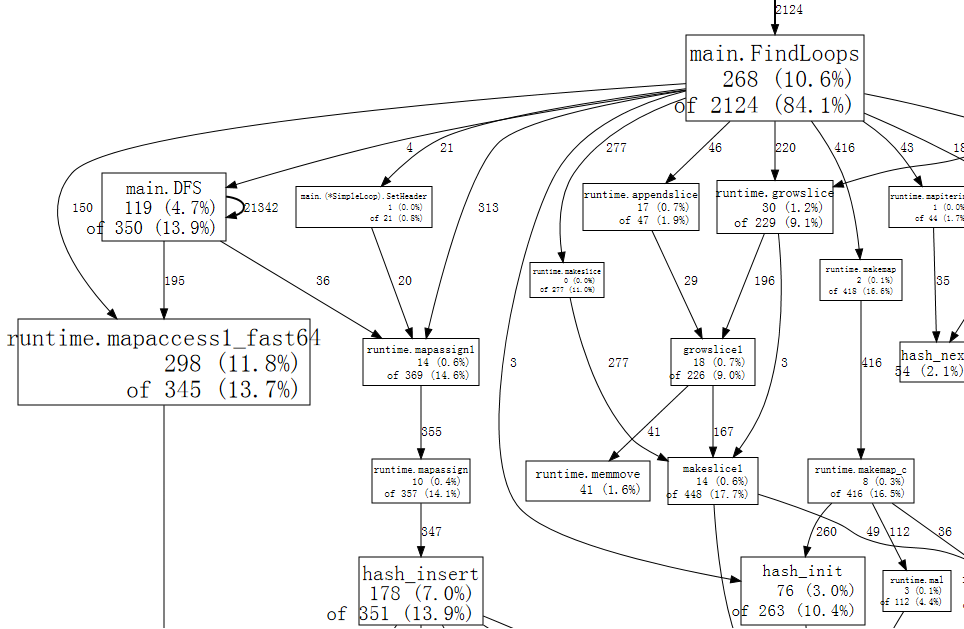
SVG를 그리고 나면, 아래와 같은 graph가 보일 것이다.

좀 더 디테일하게 한번 봐보자.

- File : 프로파일링될 바이너리 파일 이름 : gettingstarted
- Type : 프로파일 타입
- Time : 프로파일 생성된 시간
- Duration : 프로파일링이 진행된 시간
- nodes accounting for X, Y% of Z
- X 현재 프로파일에서 각 node들이 가지고 있는 샘플들의 수
- Z 프로파일에서 확인할 수 있는 모든 샘플들
- Y X/Z%를 %로 표현한 값
그리고 이제 block으로 표현되는 node들과 화살표들이 무엇인지 세부적으로 살펴보자

acyclic graph형태로 표현된 이 그래프를 보면 각 node는 하나의 함수 호출을 의미한다. 그리고 각 node안에서 각 값들이 의미하는게 무엇인지 한번 알아보자
(1) package : 패키지 이름
(2) function : 호출한 값
(3) Sample value : 해당 sample의 값
(4) Total samples of profile : 전채 샘플 값들의 합
- 요 값을 보면서 각 노드의 weight를 기준으로 프로그램의 성능에 영향을 주는 요소가 무엇인지 확인해볼 수 있음
자 이렇게 프로파일링이 무엇인지, 그리고 SVG그래프를 그렸을 때 어떻게 직관적인 insight를 얻을 수 있는지에 대해 알아보았다.
다음 글에서는 HTTP 서버를 어떻게 프로파일링 할 수 있는지에 대한 글을 작성해보겠다. profiling은 적절히 활용하면 성능 개선을 이뤄낼 수 있기 때문에 시간을 들여서 해볼만한 가치가 있다. 그럼 화이팅!

참고자료
https://hackernoon.com/go-the-complete-guide-to-profiling-your-code-h51r3waz
https://ko.wikipedia.org/wiki/프로파일링_(컴퓨터_프로그래밍)
https://medium.com/swlh/go-profile-your-code-like-a-master-1505be38fdba
https://www.practical-go-lessons.com/chap-36-program-profiling



